Git 2.53 has officially landed, bringing another round of performance optimizations, improved error messages, and bug fixes — all while inching closer to the anticipated Git 3.0 release, tentatively expected around the end of 2026.
What’s New in Git 2.53
This latest feature release delivers performance improvements across various Git sub-commands and operations, along with polished error messages and enhancements to several sub-commands. As with recent releases, the focus remains on refining the developer experience while laying the groundwork for the major 3.0 milestone.
Rust Is Now Default-Enabled
The most notable change in Git 2.53 is that both the Makefile and Meson build systems now enable Rust support by default. This means builds will fail out of the box if Rust isn’t available on the host — though developers can still explicitly disable it via build flags for the time being.
This follows a deliberate three-stage rollout:
Git 2.52 — Rust support was auto-detected by Meson and disabled in the Makefile, allowing the project to establish the initial infrastructure.
Git 2.53 (current) — Both build systems default-enable Rust. Builds break without it unless explicitly disabled.
Git 3.0 — Rust becomes mandatory. The opt-out build flags will be removed entirely.
Why Rust?
The push toward Rust in Git mirrors a broader trend across foundational open-source projects (the Linux kernel, Coreutils, zlib) that are adopting Rust for its memory safety guarantees and strong performance characteristics. For a tool as universally relied upon as Git, reducing the surface area for memory-related bugs is a significant long-term investment.
Looking Ahead
With Git 3.0 on the horizon, expect Rust to become a hard build requirement. If you maintain custom Git builds or packaging pipelines, now is the time to ensure your toolchains include a supported Rust compiler. The transition window is closing.
iXsystems lays out its roadmap for the year — an annual release cadence, cloud-style fleet management, and hardware pushing 1 PB per rack unit.
~500K
Systems Deployed
60%+
Fortune 500 Usage
1 PB
NVMe per 1U
📍
Where TrueNAS Stands Today
25.10 “Goldeye” is the recommended version for new deployments, now at GA. 25.04 “Fangtooth” remains best for mission-critical stability. 24.x & 13.0 are end-of-life — no further updates.
🚀
TrueNAS 26 — Annual Releases, No More Fish
A shift to annual releases with simple version numbers (26.1, 26.2…) instead of fish code names. Beta arrives in April 2026 with an extended development cycle for more thorough testing and predictable upgrades.
Unified management for multiple TrueNAS systems, data stays on-prem. Three tiers rolling out through the year:
Foundation (free) — headless setup & config. Plus (Q1, subscription) — replication, Webshare, ransomware protection. Business (Q2) — HA systems, large fleets, MSPs. Early adopters get 50% off the first year.
⚡
Hardware — Terabit Networking & Petabyte Density
The R60 brings 5th-gen hardware with 400GbE and RDMA for AI, video editing, and data science. H-Series hybrid systems mix NVMe and HDDs at 80% lower cost per TB than all-flash.
OpenZFS 2.4 adds intelligent tiering — hot data pinned to flash, cold data on spinning disk. With 122TB SSDs now available, a single 1U can house over 1 PB of NVMe storage.
🎯
The Bottom Line
The theme is clear: own your data. Predictable costs, no vendor lock-in, open-source foundations you can verify. TrueNAS 26 simplifies the release model, Connect simplifies fleet management, and the hardware lineup covers everything from edge deployments to petabyte-scale AI workloads.
Take full control of your Anki flashcard syncing. A self-hosted sync server with user management, TLS, backups, and metrics — packaged for one-click install on TrueNAS.
Why Self-Host Your Anki Sync?
Anki is the gold standard for spaced repetition learning — used by medical students, language learners, and lifelong learners worldwide. By default, Anki syncs through AnkiWeb, Anki’s official cloud service. But there are good reasons to run your own sync server: full ownership of your data, no upload limits, the ability to share a server with a study group, and the peace of mind that comes with keeping everything on your own hardware.
Anki Sync Server Enhanced wraps the official Anki sync binary in a production-ready Docker image with features you’d expect from a proper self-hosted service — and it’s now submitted to the TrueNAS Community App Catalog for one-click deployment.
What’s Included
🔐
User Management
Create sync accounts via environment variables. No database setup required.
🔒
Optional TLS
Built-in Caddy reverse proxy for automatic HTTPS with Let’s Encrypt or custom certs.
💾
Automated Backups
Scheduled backups with configurable retention and S3-compatible storage support.
📊
Metrics & Dashboard
Prometheus-compatible metrics endpoint and optional web dashboard for monitoring.
🐳
Docker Native
Lightweight Debian-based image. Runs as non-root. Healthcheck included.
⚡
TrueNAS Ready
Submitted to the Community App Catalog. Persistent storage, configurable ports, resource limits.
How It Works
Anki Desktop / Mobile→Anki Sync Server Enhanced→TrueNAS Storage
Your Anki clients sync directly to your TrueNAS server over your local network or via Tailscale/WireGuard.
The server runs the official anki-sync-server Rust binary — the same code that powers AnkiWeb — inside a hardened container. Point your Anki desktop or mobile app at your server’s URL, and syncing works exactly like it does with AnkiWeb, just on your own infrastructure.
TrueNAS Installation
Once the app is accepted into the Community train, installation is straightforward from the TrueNAS UI. In the meantime, you can deploy it as a Custom App using the Docker image directly.
PR Status: The app has been submitted to the TrueNAS Community App Catalog via PR #4282 and is awaiting review. Track progress on the app request issue #4281.
To deploy as a Custom App right now, use these settings:
Setting
Value
Image
chrislongros/anki-sync-server-enhanced
Tag
25.09.2-1
Port
8080 (or any available port)
Environment: SYNC_USER1
yourname:yourpassword
Environment: SYNC_PORT
Must match your chosen port
Storage: /data
Host path or dataset for persistent data
Connecting Your Anki Client
After the server is running, configure your Anki client to use it. In Anki Desktop, go to Tools → Preferences → Syncing and set the custom sync URL to your server address, for example http://your-truenas-ip:8080. On AnkiDroid, the setting is under Settings → Sync → Custom sync server. On AnkiMobile (iOS), look under Settings → Syncing → Custom Server.
Then simply sync as usual — your Anki client will talk to your self-hosted server instead of AnkiWeb.
Building It: Lessons from TrueNAS App Development
Packaging a Docker image as a TrueNAS app turned out to involve a few surprises worth sharing for anyone considering contributing to the catalog.
TrueNAS apps use a Jinja2 templating system backed by a Python rendering library — not raw docker-compose files. Your template calls methods like Render(values), c1.add_port(), and c1.healthcheck.set_test() which generate a validated compose file at deploy time. This means you get built-in support for permissions init containers, resource limits, and security hardening for free.
One gotcha: TrueNAS runs containers as UID/GID 568 (the apps user), not root. If your entrypoint writes to files owned by a different user, it will fail silently or crash. We hit this with a start_time.txt write and had to make it non-fatal. Another: the Anki sync server returns a 404 on / (it has no landing page), so the default curl --fail healthcheck marks the container as unhealthy. Switching to a TCP healthcheck solved it cleanly.
The TrueNAS CI tooling is solid — a single ci.py script renders your template, validates the compose output, spins up containers, and checks health status. If the healthcheck fails, it dumps full container logs and inspect data, making debugging fast.
Get Involved
Ready to Self-Host Your Anki Sync?
Deploy it on TrueNAS today or star the project on GitHub to follow development.
Claude Opus 4.6: Anthropic’s Most Capable Model Yet
Published February 6, 2026 — 8 min read
On February 5, 2026, Anthropic released Claude Opus 4.6 — its most powerful AI model to date. Arriving just three months after Opus 4.5, this update delivers a massive expansion to the context window, a new “agent teams” paradigm for parallel task execution, and benchmark scores that surpass both OpenAI’s GPT-5.2 and Google’s Gemini 3 Pro across a range of evaluations.
Whether you’re a developer building agentic workflows, a knowledge worker producing professional documents, or a researcher wrestling with enormous datasets, Opus 4.6 marks a tangible leap in what an AI model can handle in a single session.
1MToken context window (beta)
128KMax output tokens
68.8%ARC AGI 2 score
$5 / $25Input / output per 1M tokens
What’s New in Opus 4.6
While the version bump from 4.5 to 4.6 may seem incremental, the changes under the hood are substantial. Anthropic has focused on three pillars: reasoning depth, context capacity, and agentic execution.
⚡
1 Million Token Context Window A 5× increase over the previous 200K limit. Opus 4.6 scores 76% on the MRCR v2 needle-in-a-haystack benchmark at 1M tokens, compared to just 18.5% for Sonnet 4.5 — a qualitative shift in usable context.
🤖
Agent Teams in Claude Code Multiple specialised agents can now split a task and work in parallel — one on the frontend, one on the API, one on a migration — coordinating autonomously. Anthropic reports a roughly 30% reduction in end-to-end task runtime.
🧠
Adaptive Thinking Replaces the binary on/off extended thinking toggle. Opus 4.6 dynamically decides how much reasoning effort a prompt requires. Four effort levels (low, medium, high, max) give developers fine-grained cost–speed–quality control.
♾️
Context Compaction API A new beta feature that automatically summarises older context as conversations grow, enabling effectively infinite sessions without manual truncation or sliding-window hacks.
📊
Claude in PowerPoint & Excel Updates Claude now operates as a side panel inside PowerPoint, respecting your slide masters and layouts. Excel gets unstructured data support and longer workflows for paid subscribers.
Benchmark Breakdown
Opus 4.6 sets new state-of-the-art scores on several major evaluations. The most striking result is on ARC AGI 2, a benchmark designed to measure novel problem-solving that is easy for humans but notoriously hard for AI. Opus 4.6 scored 68.8% — nearly double Opus 4.5’s 37.6% and well ahead of GPT-5.2 (54.2%) and Gemini 3 Pro (45.1%).
Benchmark
Opus 4.6
Opus 4.5
GPT-5.2
Gemini 3 Pro
Terminal Bench 2.0
65.4%
59.8%
—
—
OSWorld (Agentic)
72.7%
66.3%
< 72.7%
< 72.7%
ARC AGI 2
68.8%
37.6%
54.2%
45.1%
MRCR v2 (1M ctx)
76%
—
—
—
Humanity’s Last Exam
#1
—
—
—
Beyond the headline numbers, Opus 4.6 also tops the GDPval-AA benchmark for economically valuable knowledge work, outperforming GPT-5.2 by approximately 144 ELO points. In life sciences, it delivers nearly twice the performance of its predecessor on computational biology, structural biology, organic chemistry, and phylogenetics tests.
Coding and Developer Impact
Coding has always been a strength of the Opus line, and 4.6 takes it further. The model plans more carefully before generating code, catches its own mistakes through improved self-review, and sustains agentic tasks for longer without losing coherence. For large codebases, Anthropic claims it can now handle autonomous code review, debugging, and refactoring across repositories that would have previously required human intervention.
“Opus 4.6 is a model that makes the shift from chatbot to genuine work partner really concrete for our users.”
— Scott White, Head of Product, Anthropic
The new agent teams feature in Claude Code is particularly noteworthy. Rather than a single agent working sequentially, developers can now spin up parallel agents that own distinct parts of a task. Anthropic’s example: one agent handles the frontend, another the API layer, and a third manages database migrations — all coordinating autonomously. This is available as a research preview and represents a meaningful step towards multi-agent orchestration out of the box.
Enterprise and Knowledge Work
Anthropic has been explicit about targeting enterprise workflows with this release. Roughly 80% of the company’s business comes from enterprise customers, and Opus 4.6 is tuned for the kind of work they care about: financial analysis, legal research, document production, and multi-step research tasks.
The model now leads on the Finance Agent benchmark and TaxEval by Vals AI. Combined with the expanded context window, analysts can feed entire filings, market reports, and internal data into a single session and get coherent, cross-referenced outputs. Anthropic says Opus 4.6 produces documents, spreadsheets, and presentations that approach expert-created quality on the first pass, reducing the rework cycle significantly.
💡 Pricing NoteStandard API pricing remains at $5 input / $25 output per million tokens — identical to Opus 4.5. Requests exceeding 200K input tokens are charged at a premium rate of $10 / $37.50 per MTok. The model is available via the Anthropic API, AWS Bedrock, Google Vertex AI, Microsoft Foundry, and directly on claude.ai.
Availability and API Changes
Opus 4.6 is live now across all major platforms. The API model identifier is simply claude-opus-4-6 — note the simplified naming without a date suffix. It’s available on the Anthropic API, AWS Bedrock, Google Vertex AI, Microsoft Foundry, and through GitHub Copilot for Pro, Pro+, Business, and Enterprise users.
Developers should be aware of a few breaking changes: assistant message prefilling now returns a 400 error (migrate to structured outputs or system prompt instructions), the output_format parameter has moved to output_config.format, and the effort parameter is now generally available without a beta header.
Safety and Alignment
Anthropic reports that the intelligence gains in Opus 4.6 have not come at the cost of safety. On their automated behavioural audit, the model showed low rates of misaligned behaviours including deception, sycophancy, and encouragement of user delusions — matching Opus 4.5’s results. Six new cybersecurity probes have been added to evaluate potential misuse vectors, and the model achieves a lower rate of unnecessary refusals compared to previous releases.
The Bigger Picture
Opus 4.6 arrives at a moment of intensifying competition. OpenAI announced its new OpenAI Frontier enterprise platform just hours before Anthropic’s launch, signalling a strategic pivot towards infrastructure and agent management rather than competing purely on benchmark scores. Google’s Gemini 3 Pro and Microsoft’s deep integration of Opus 4.6 into Foundry add further complexity to the landscape.
What sets this release apart is the combination of raw capability and practical utility. The 1M context window, agent teams, adaptive thinking, and context compaction aren’t just benchmark optimisations — they address real friction points that developers and knowledge workers hit daily. If Opus 4.5 moved Claude from “chatbot” to “useful tool,” Opus 4.6 positions it as a genuine work partner that can own entire workflows end-to-end.
For those already running Opus 4.5 in production, the upgrade path is a single API version change at the same price point. For everyone else, this is a strong argument to take a serious look at what Claude can do in 2026.
Two major releases of rfsrs are now available, bringing custom parameter support, SM-2 migration tools, and — the big one — parameter optimization. You can now train personalized FSRS parameters directly from your Anki review history using R.
Version 0.2.0: Custom Parameters & SM-2 Migration
Critical Bug Fix
Version 0.1.0 had a critical bug: custom parameters were silently ignored. The Scheduler stored your parameters but all Rust calls used the defaults. This is now fixed — your custom parameters actually work.
New Features in 0.2.0
Preview All Rating Outcomes
fsrs_repeat() returns all four rating outcomes (Again/Hard/Good/Easy) in a single call, matching the py-fsrs API:
# See all outcomes at once
outcomes <- fsrs_repeat(
stability = 10,
difficulty = 5,
elapsed_days = 5,
desired_retention = 0.9
)
outcomes$good$stability # 15.2
outcomes$good$interval # 12 days
outcomes$again$stability # 3.1
SM-2 Migration
Migrating from Anki’s default algorithm? fsrs_from_sm2() converts your existing ease factors and intervals to FSRS memory states:
# Convert SM-2 state to FSRS
state <- fsrs_from_sm2(
ease_factor = 2.5,
interval = 30,
sm2_retention = 0.9
)
state$stability # ~30 days
state$difficulty # ~5
Compute State from Review History
fsrs_memory_state() replays a sequence of reviews to compute the current memory state:
# Replay review history
state <- fsrs_memory_state(
ratings = c(3, 3, 4, 3), # Good, Good, Easy, Good
delta_ts = c(0, 1, 3, 7) # Days since previous review
)
state$stability
state$difficulty
Vectorized Operations
fsrs_retrievability_vec() efficiently calculates recall probability for large datasets:
# Calculate retrievability for 10,000 cards
retrievability <- fsrs_retrievability_vec(
stability = cards$stability,
elapsed_days = cards$days_since_review
)
Scheduler Improvements
Scheduler$preview_card() — see all outcomes without modifying the card
Card$clone_card() — deep copy a card for simulations
fsrs_simulate() — convenience function for learning simulations
State transitions now correctly match py-fsrs/rs-fsrs behavior
Version 0.3.0: Parameter Optimizer
The most requested feature: train your own FSRS parameters from your review history.
Why Optimize?
FSRS uses 21 parameters to predict when you’ll forget a card. The defaults work well for most people, but training custom parameters on your review history can improve scheduling accuracy by 10-30%.
New Functions in 0.3.0
fsrs_optimize() — Train custom parameters from your review history
fsrs_evaluate() — Measure how well parameters predict your memory
fsrs_anki_to_reviews() — Convert Anki’s revlog format for optimization
Optimize Your Parameters
Here’s how to train parameters using your Anki collection:
The optimizer uses machine learning (via the burn framework in Rust) to find parameters that best predict your actual recall patterns. It analyzes your review history to learn:
How quickly you initially learn new cards
How your memory decays over time
How different ratings (Again/Hard/Good/Easy) affect retention
I tested it on my own collection with ~116,000 reviews across 5,800 cards — optimization took about 60 seconds.
Compare Parameters
Evaluate how well different parameters predict your memory:
Damien Elmes says he’s stepping back from being Anki’s bottleneck—without saying goodbye.
Anki’s creator, Damien Elmes (often known as “dae”), shared a major update about the future of Anki: after nearly two decades of largely solo stewardship, he intends to gradually transition business operations and open-source stewardship to the team behind AnkiHub.
The headline reassurance is clear: Anki is intended to remain open source, and the transition is framed as a way to make development more sustainable, reduce single-person risk, and accelerate improvements—especially long-requested quality-of-life and UI polish.
Why this change is happening
Damien described a familiar pattern for long-running open-source projects: as Anki grew in popularity, demands on his time increased dramatically. Over time, the work shifted away from “deep work” (solving interesting technical problems) toward reactive support, constant interruptions, and the stress of feeling responsible for millions of users.
Time pressure and stress: Unsustainably long hours began affecting well-being and relationships.
Delegation limits: Paying prolific contributors helped, but many responsibilities remained hard to delegate.
Bottleneck risk: Relying on one person puts the entire ecosystem at risk if they become unavailable.
Why AnkiHub?
According to the announcement, AnkiHub approached Damien about closer collaboration to improve Anki’s development pace. Through those conversations, Damien concluded that AnkiHub is better positioned to help Anki “take the next level,” in part because they’ve already built a team and operational capacity.
Crucially, Damien also emphasized that he has historically rejected buyout or investment offers due to fears of “enshittification” and misaligned incentives. This new transition is presented as different: it aims to preserve Anki’s values and open-source nature, while removing the single-person bottleneck.
“This is a step back for me rather than a goodbye — I will still be involved with the project, albeit at a more sustainable level.”
What AnkiHub says they believe
In their reply, AnkiHub emphasized that Anki is “bigger than any one person or organization” and belongs to the community. They echoed the principles associated with Anki’s development: respect for user agency, avoiding manipulative design patterns, and focusing on building genuinely useful tools rather than engagement traps.
Commitments and reassurances
Open source: Anki’s core code is intended to remain open source.
No investors: They state there are no outside investors influencing decisions.
No pricing changes planned: They explicitly say no changes to Anki pricing are planned.
Not a financial rescue: They say Anki is not in financial trouble; this is about improving capacity and resilience.
Mobile apps continue: They say mobile apps will remain supported and maintained.
AnkiDroid remains independent: They state there are no plans/agreements changing AnkiDroid’s self-governance.
What might improve (and why users should care)
If the transition works as intended, users may see benefits in areas that are hard to prioritize under constant time pressure:
Faster development: More people can work without everything bottlenecking through one person.
UI/UX polish: Professional design support to make Anki more approachable without losing power.
Better onboarding: Improved first-run experience and fewer rough edges for beginners.
Lower “bus factor”: Reduced risk if any one contributor disappears.
Open questions
AnkiHub also acknowledged that many details are still undecided and invited community input. Areas still being worked out include:
Governance: How decisions are made, who has final say, and how community feedback is incorporated.
Roadmap: What gets built when, and how priorities are balanced.
Transition mechanics: How support scales up without breaking what already works.
FAQ
Will Anki remain open source?
Yes. Both Damien and AnkiHub explicitly frame the transition around keeping Anki’s core open source and aligned with the principles the project has followed for years.
Is this a sale or VC takeover?
The announcement positions this as a stewardship transition, not a typical investor-led acquisition. AnkiHub states there are no outside investors involved.
Are pricing changes coming?
AnkiHub says no pricing changes are planned and emphasizes affordability and accessibility.
What about mobile and AnkiDroid?
They say mobile apps will remain supported. AnkiDroid is described as continuing as an independent, self-governed open-source project.
Bottom line
Damien isn’t leaving—he’s stepping back to a more sustainable role. The goal is to remove a long-standing bottleneck, reduce ecosystem risk, and speed up improvements without compromising what makes Anki special.
If you’ve wanted faster progress, better UI polish, and a more resilient future for Anki—this transition is designed to make that possible, while keeping the project open source and community-oriented.
Published: February 2, 2026 • Category: Announcements • Tags: Anki, Open Source, AnkiHub, Study Tools
After years of using Anki for medical school, I finally got tired of relying on AnkiWeb for syncing. Privacy concerns, sync limits, and the occasional downtime pushed me to self-host. The problem? The official Anki project provides source code but no pre-built Docker image. Building from source every time there’s an update? No thanks.
So I built Anki Sync Server Enhanced — a production-ready Docker image with all the features self-hosters actually need.
Why Self-Host Your Anki Sync?
Privacy — Your flashcards stay on your server
No limits — Sync as much as you want
Speed — Local network sync is instant
Control — Backups, monitoring, your rules
What Makes This Image Different?
I looked at existing solutions and found them lacking. Most require you to build from source or offer minimal features. Here’s what this image provides out of the box:
Feature
Build from Source
This Image
Pre-built Docker image
No
Yes
Auto-updates
Manual
Daily builds via GitHub Actions
Multi-architecture
Manual setup
amd64 + arm64
Automated backups
No
Yes, with retention policy
S3 backup upload
No
Yes (AWS, MinIO, Garage)
Prometheus metrics
No
Yes
Web dashboard
No
Yes
Notifications
No
Discord, Telegram, Slack, Email
Quick Start
Getting started takes less than a minute:
docker run -d \
--name anki-sync \
-p 8080:8080 \
-e SYNC_USER1=myuser:mypassword \
-v anki_data:/data \
chrislongros/anki-sync-server-enhanced
That’s it. Your sync server is running.
Docker Compose (Recommended)
For a more complete setup with backups and monitoring:
If you’re using Anki seriously — for medical school, language learning, or any knowledge work — self-hosting your sync server gives you complete control over your data. This image makes it as simple as a single Docker command.
Questions or feature requests? Open an issue on GitHub or leave a comment below.
Immich, the popular open-source, self-hosted photo and video management solution, has launched a community-driven initiative to improve its metadata handling capabilities. Through the new EXIF Dataset project, users can contribute their photos to help train and improve Immich’s EXIF parsing and metadata extraction features.
I recently contributed some of my own photos to the project, and I want to share how easy and straightforward the process is. If you’re an Immich user (or simply an open-source enthusiast), this is a fantastic way to give back to the community.
What is the EXIF Dataset Project?
EXIF (Exchangeable Image File Format) data is the metadata embedded in your photos by your camera or smartphone. This includes information like the camera make and model, date and time, GPS coordinates, lens information, and much more. Immich uses this data extensively to organize your photo library, enable timeline views, power location-based features, and facilitate powerful search capabilities.
The EXIF Dataset project at datasets.immich.app/projects/exif allows community members to contribute photos along with their intact EXIF metadata. This crowdsourced dataset helps the Immich team understand how different cameras and devices encode their metadata, ultimately improving compatibility and parsing accuracy for everyone.
The contribution process is remarkably simple and well-designed. Here’s how it works:
Step 1: Upload Your Photos
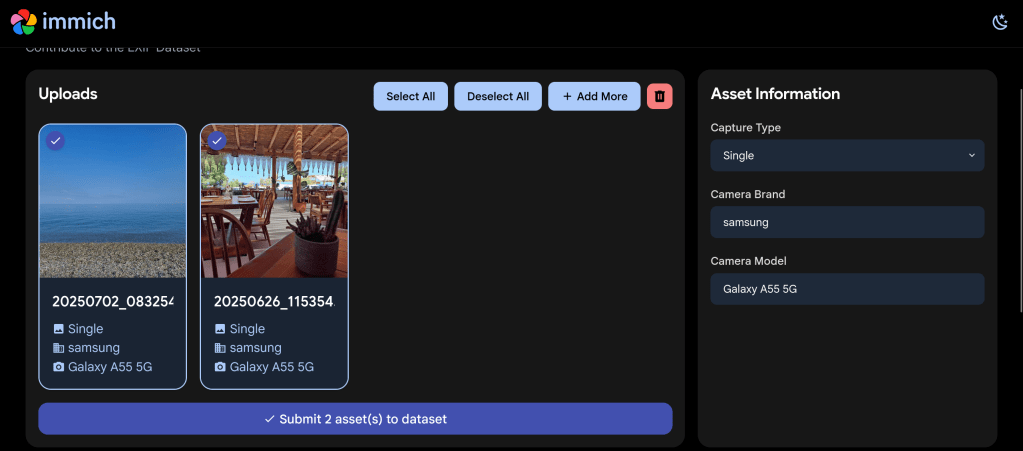
After navigating to the EXIF Dataset project page, you’re greeted with a clean upload interface. I uploaded a couple of photos taken with my Samsung Galaxy A55 5G – a beach landscape shot and a photo from a beachside restaurant.
The clean upload interface showing my first selected photo with its EXIF metadata displayed
The interface immediately displays the extracted EXIF information on the right side, including the capture type (Single), camera brand (Samsung), and camera model (Galaxy A55 5G). This lets you verify that your photos contain the metadata you want to contribute.
Step 2: Select Photos for Submission
You can upload multiple photos at once using the “+ Add More” button. I selected both of my photos for contribution – each showing clearly with a checkmark indicating selection.
Two photos selected and ready to submit to the EXIF Dataset
The interface provides convenient “Select All” and “Deselect All” buttons, as well as a delete option if you change your mind about any uploads.
Step 3: Agree to the CC0 License
When you click “Submit asset(s) to dataset”, a Dataset Agreement dialog appears. This is where the legal side of your contribution is handled transparently.
The Dataset Agreement confirms your photos will be released under the CC0 public domain license
ℹ️ About CC0: The CC0 (Creative Commons Zero) license means you’re releasing your contributed photos into the public domain. This allows the Immich project (and anyone else) to use the images freely for any purpose. Make sure you only upload photos you own the rights to and are comfortable sharing publicly.
The agreement requires you to confirm two things:
You agree to release the uploaded assets under the CC0 license into the public domain
The files have not been modified in any way that would alter their original content or metadata
You also provide a contact email in case the Immich team has any questions about your upload.
Why Should You Contribute?
Contributing to the EXIF Dataset helps improve Immich in several ways:
Better Device Support: By collecting EXIF samples from many different cameras and phones, Immich can improve its parsing for devices that may have quirks or non-standard metadata encoding
Improved Metadata Extraction: The dataset helps identify edge cases and unusual metadata formats that might otherwise go unnoticed
Community-Driven Development: Your contribution directly influences the quality of an open-source project used by thousands of self-hosters worldwide
Supporting Privacy-Focused Software: Immich is a privacy-respecting alternative to cloud-based photo services like Google Photos – your contribution helps make it even better
Tips for Contributing
To make your contribution as valuable as possible:
Contribute from different devices: If you have photos from older cameras, different smartphone brands, or professional equipment, these are especially valuable
Keep metadata intact: Don’t strip or modify the EXIF data before uploading – the original metadata is exactly what’s needed
Consider variety: Photos taken in different conditions (indoor, outdoor, various lighting) may contain different metadata values
Check your ownership: Only contribute photos you’ve taken yourself or have explicit rights to share
About Immich
For those unfamiliar with Immich, it’s a high-performance, self-hosted photo and video management solution that offers features comparable to Google Photos – but with full control over your data. Key features include automatic backup from mobile devices, facial recognition, smart search, timeline views, shared albums, and much more.
Immich is developed under the AGPL-3.0 license and is backed by FUTO, an organization dedicated to developing privacy-preserving technology. The project has grown tremendously, with over 77,000 stars on GitHub, making it one of the most popular self-hosted applications available.
🏠 Self-Host Immich: Get started with Immich at immich.app – available for Docker, TrueNAS, Unraid, and other platforms.
Conclusion
Contributing to the Immich EXIF Dataset is a simple yet meaningful way to support open-source software development. The process takes just a few minutes, and your contribution will help improve photo management for the entire Immich community.
GitHub has officially rolled out the improved “Files Changed” experience as the default for all users. After months in public preview, this redesigned pull request review interface brings significant improvements to performance, accessibility, and overall productivity when reviewing code changes.
Key Improvements Over the Classic Experience
The new interface maintains familiarity for existing users while adding several notable enhancements:
Comment on Any Line
Previously, you could only comment on lines directly surrounding a change. Now you can add review comments to any line in a changed file, making it easier to provide context or point out related code that might need attention.
View PR Description Without Switching Pages
A new Overview panel lets you view the pull request description directly from the “Files changed” page. No more jumping back and forth between tabs to remember what the PR is supposed to accomplish.
Enhanced File Tree
The file tree sidebar is now resizable and includes visual indicators showing which files have comments, errors, or warnings. This makes it much easier to track your progress when reviewing large PRs with many changed files.
Draft Comments That Persist
Comments and replies are now saved locally in your browser. If you accidentally close the tab or refresh the page, your in-progress feedback won’t be lost.
Fewer Page Reloads
Actions like refreshing to pull in new changes, switching between split and unified diff modes, and other common tasks no longer force a full page reload. The interface feels much snappier as a result.
Improved Accessibility
The new experience includes better keyboard navigation, screen reader landmarks, and increased line spacing options to make code review accessible to everyone.
Experimental Mode for Large Pull Requests
One of the most interesting additions is an experimental mode specifically designed for reviewing large pull requests. This mode uses virtualization to reduce the number of DOM elements the browser needs to manage, significantly improving memory usage and page responsiveness—especially on slower machines.
When viewing a large PR, you’ll see a banner offering to try this experimental mode. There are some trade-offs: browser find functionality, text selection across the entire page, printing, and some browser extensions may not work as expected since the full diff isn’t rendered in the DOM. You can switch back to single file mode at any time.
Bug Fixes and Polish
GitHub has also addressed numerous issues including problems with suggested changes being applied incorrectly, comment workflow bugs, interaction lag (especially on Safari), and various UI quirks like scroll positioning and sticky headers behaving unexpectedly.
Opting Out
If you prefer the classic experience, you can still opt out through your settings. However, given the improvements in this new version, it’s worth giving it a fair trial before switching back.
Providing Feedback
GitHub is actively collecting feedback on the new experience. If you encounter issues or have suggestions, you can participate in the “Files Changed” preview feedback discussion on GitHub.
If you’re using Tailscale with Mullvad VPN (either via the native Tailscale integration or standalone) and Firefox’s DNS over HTTPS (DoH), you might suddenly find yourself unable to access your Tailscale services via their *.ts.net hostnames—even though everything worked fine before.
The symptoms are frustrating: tailscale ping works, dig resolves the hostname correctly, but Firefox just refuses to connect.
Why This Happens
When you enable DNS over HTTPS in Firefox (especially with “Max Protection” mode), Firefox bypasses your system’s DNS resolver entirely and sends all DNS queries directly to your chosen DoH provider—in this case, Mullvad’s DNS server at https://base.dns.mullvad.net/dns-query.
The problem? Mullvad’s public DNS server has no idea what my-server.my-tailnet.ts.net is. That’s a private hostname that only Tailscale’s MagicDNS (running at 100.100.100.100) knows how to resolve.
So while your system can resolve the hostname just fine:
Firefox completely ignores this and asks Mullvad instead, which returns nothing.
The Solution
Firefox provides a way to exclude specific domains from DoH, forcing it to fall back to system DNS for those domains. Here’s how to set it up:
Open Firefox and navigate to about:config
Search for network.trr.excluded-domains
Add ts.net to the list (comma-separated if there are existing entries)
For example:
ts.net
Or if you have other exclusions:
example.local, ts.net
This tells Firefox: “For any domain ending in .ts.net, use the system DNS resolver instead of DoH.” Since your system DNS is controlled by Tailscale’s MagicDNS, the hostname will resolve correctly.
The Gotcha: Old Tailnet Names
Here’s a subtle issue that can trip you up: if you previously had a different Tailscale account or renamed your tailnet, you might have an old, specific exclusion that no longer applies.
For example, you might have:
my-nas.old-tailnet.ts.net
But your current tailnet is new-tailnet.ts.net. The old exclusion does nothing for your new tailnet!
The fix is simple: instead of excluding specific tailnet hostnames, just exclude the entire ts.net domain. This covers all Tailscale hostnames, regardless of your tailnet name, now and in the future.
Verifying the Fix
After making the change, you can verify everything is working:
Test Tailscale connectivity (should already work): tailscale ping your-machine-name
Test DNS resolution from the command line: dig your-machine-name.your-tailnet.ts.net
Test in Firefox: Navigate to your Tailscale hostname—it should now load.
Summary
If you’re combining Firefox DoH with Tailscale:
Firefox’s DoH bypasses Tailscale’s MagicDNS
Add ts.net to network.trr.excluded-domains in about:config
Use ts.net (not a specific tailnet name) to future-proof the setting
This gives you the best of both worlds: private DNS for general browsing via Mullvad, and working hostname resolution for your Tailscale network.