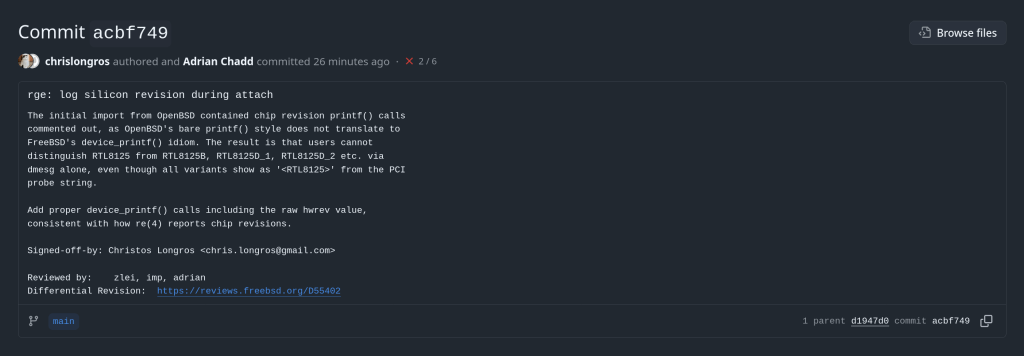
Enabling Silicon Revision Logging in FreeBSD’s rge(4) Driver
This article describes a kernel-level patch to the FreeBSD rge(4) network driver that enables proper identification of Realtek RTL8125/8126/8127 silicon variants at attach time. The change is small but reveals an interesting idiom gap between two BSD kernels.
The rge(4) Driver and Its Hardware
The rge(4) driver supports a family of Realtek multi-gigabit NICs spanning three product generations. Despite sharing a common PCI device ID tree, each silicon revision has meaningfully different characteristics: different firmware images, different register maps for some functions, and different feature sets.
| Chip | hwrev register | Type constant | Generation |
|---|
| RTL8125 | 0x60900000 | MAC_R25 | 2.5GbE first gen |
| RTL8125B | 0x64100000 | MAC_R25B | 2.5GbE revised |
| RTL8125D_1 | 0x68800000 | MAC_R25D | 2.5GbE third gen |
| RTL8125D_2 | 0x68900000 | MAC_R25D | 2.5GbE third gen alt |
| RTL8126_1 | 0x64900000 | MAC_R26 | 5GbE first gen |
| RTL8126_2 | 0x64a00000 | MAC_R26 | 5GbE alt |
| RTL8127 | 0x6c900000 | MAC_R27 | 10GbE |
The hardware revision is detected by reading the RGE_TXCFG register and masking off the lower bits, yielding the hwrev value. This happens in rge_get_macaddr() via the attachment path in rge_attach().
How Hardware Revision Detection Works
The detection is a straightforward switch statement in sys/dev/rge/if_rge.c:
hwrev = CSR_READ_4(sc, RGE_TXCFG) & RGE_TXCFG_HWREV;
switch (hwrev) {
case 0x60900000:
sc->rge_type = MAC_R25;
break;
case 0x64100000:
sc->rge_type = MAC_R25B;
break;
/* ... */
}
The rge_type field stored in the softc structure is then used throughout the driver to select chip-specific paths — for example, firmware loading, ring configuration, and certain register sequences differ between MAC_R25 and MAC_R25B.
The Problem: Invisible Chip Identification
Before the patch, despite detecting seven distinct silicon variants at runtime, the driver logged nothing about which one was found. All three product families produce dmesg output that looks like this:
pci0: <network> at device 0.0 (no driver attached)
rge0: <RTL8125> mem 0xfc400000-0xfc40ffff [...] at device 0.0 on pci2
rge0: Using 1 MSI-X message
rge0: CHIP: 0x00000000
miibus0: <MII bus> on rge0
The string <RTL8125> comes from the PCI probe function — specifically device_set_desc() — which is set once during probe based on the PCI subsystem ID, before the hardware revision register is even read. It cannot distinguish RTL8125 from RTL8125B, or RTL8126_1 from RTL8126_2. A user filing a bug report, or a developer debugging an issue specific to one silicon stepping, had no way to confirm which variant was present without writing custom code to read RGE_TXCFG manually.
The OpenBSD Import and the Commented Code
Examining the original import commit reveals that identification prints were always present in the source — just commented out in a non-idiomatic style:
case 0x60900000:
sc->rge_type = MAC_R25;
// device_printf(dev, "RTL8125\n");
break;
case 0x64100000:
sc->rge_type = MAC_R25B;
// device_printf(dev, "RTL8125B\n");
break;
The use of // comments is itself a signal: the FreeBSD kernel style guide mandates /* */ C89-style comments for all kernel code. The // style is characteristic of code copied directly from another source and then quickly commented out.
The origin is OpenBSD’s sys/dev/pci/if_rge.c, where the equivalent identification uses a different printing idiom:
/* OpenBSD style — appends to the in-progress attach line */
case 0x64100000:
sc->rge_type = MAC_R25B;
printf(": RTL8125B");
break;
In OpenBSD, the device attachment infrastructure prints the device name on a line and drivers call bare printf() to append chip identification to that same line, producing output like:
rge0 at pci2 dev 0 function 0 "Realtek 8125" rev 0x00: RTL8125B, ...
FreeBSD’s driver framework does not work this way. device_printf(dev, ...) always begins a new line prefixed with the device name — it cannot append to an existing line. A direct translation of the OpenBSD bare printf() would either produce garbled output or nothing useful. Rather than translating the idiom at import time, the prints were commented out.
The Fix
The correct FreeBSD idiom is device_printf() on its own line, following attach. The patch enables all seven commented prints in the proper style, and adds the raw hwrev register value alongside the human-readable name — consistent with how the re(4) driver reports chip revisions:
switch (hwrev) {
case 0x60900000:
sc->rge_type = MAC_R25;
device_printf(dev, "chip rev: RTL8125 (0x%08x)\n", hwrev);
break;
case 0x64100000:
sc->rge_type = MAC_R25B;
device_printf(dev, "chip rev: RTL8125B (0x%08x)\n", hwrev);
break;
case 0x64900000:
sc->rge_type = MAC_R26_1;
device_printf(dev, "chip rev: RTL8126_1 (0x%08x)\n", hwrev);
break;
case 0x64a00000:
sc->rge_type = MAC_R26_2;
device_printf(dev, "chip rev: RTL8126_2 (0x%08x)\n", hwrev);
break;
case 0x68800000:
sc->rge_type = MAC_R25D;
device_printf(dev, "chip rev: RTL8125D_1 (0x%08x)\n", hwrev);
break;
case 0x68900000:
sc->rge_type = MAC_R25D;
device_printf(dev, "chip rev: RTL8125D_2 (0x%08x)\n", hwrev);
break;
case 0x6c900000:
sc->rge_type = MAC_R27;
device_printf(dev, "chip rev: RTL8127 (0x%08x)\n", hwrev);
break;
}
Including the raw hex value serves two purposes. First, it allows unambiguous identification even if the human-readable label ever becomes incorrect or incomplete. Second, it mirrors the diagnostic value already present in the CHIP: line printed slightly later in attach, but associates it directly with the revision identification step.
Result: Before and After
After the patch, a system with an RTL8125B produces:
rge0: <RTL8125> mem 0xfc400000-0xfc40ffff [...] at device 0.0 on pci2
rge0: chip rev: RTL8125B (0x64100000)
rge0: Using 1 MSI-X message
A system with RTL8126_1 (a 5GbE part that probes as <RTL8126>) produces:
rge0: <RTL8126> mem 0xfc400000-0xfc40ffff [...] at device 0.0 on pci2
rge0: chip rev: RTL8126_1 (0x64900000)
rge0: Using 1 MSI-X message
The chip revision is now permanently captured in dmesg(8) output and system logs, available without any special tools or kernel knowledge.
Why the Raw hwrev Value Matters
The hwrev bitmask is read from bits [31:20] of RGE_TXCFG. Realtek does not publish full public documentation for these register fields, and the driver’s variant table has been built incrementally as new silicon steppings were encountered in the wild. Including the raw value means that if a new stepping appears with an hwrev not yet in the driver’s switch statement, it will still be captured in the log — giving developers the exact value needed to add support for it.
Note on the default case: The switch has no explicit default. An unrecognized hwrev leaves rge_type at its zero-initialized value. With the patch, the raw value is logged for all handled cases, but an unknown stepping would produce no chip rev line at all — a future improvement could add a default case that logs the unknown value explicitly.
Diff Summary
The complete change touches a single file, sys/dev/rge/if_rge.c:
7 lines changed: 7 insertions(+), 7 deletions(-)
- // device_printf(dev, "RTL8125\n"); (×7 variants)
+ device_printf(dev, "chip rev: RTL8125 (0x%08x)\n", hwrev); (×7 variants)
No logic changes. No new dependencies. No behavioral differences other than the additional log line per attach.
Review
The patch is under review at reviews.freebsd.org/D55402, where it will be integrated into the broader rge(4) improvement stack for the upcoming development cycle.