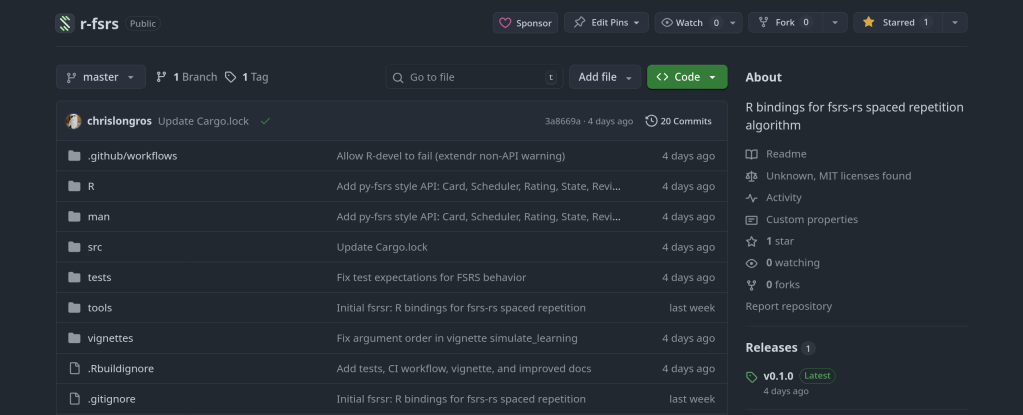
-
Unlock insights from your spaced repetition learning journey
If you’re serious about learning, chances are you’ve encountered Anki—the powerful, open-source flashcard application that uses spaced repetition to help you remember anything. Whether you’re studying medicine, languages, programming, or any other subject, Anki has likely become an indispensable part of your learning toolkit.
But have you ever wondered what stories your flashcard data could tell? How your review patterns have evolved over time? Which decks demand the most cognitive effort? That’s exactly why I created ankiR.
What is ankiR?
ankiR is an R package that lets you read, analyze, and visualize your Anki collection data directly in R. Under the hood, Anki stores all your notes, cards, review history, and settings in a SQLite database. ankiR provides a clean, user-friendly interface to access this treasure trove of learning data.
Installation
ankiR is available on CRAN and R-universe, making installation straightforward:
From CRAN
install.packages("ankiR")From R-universe (development version)
# Enable the r-universe repositoryoptions(repos = c(chrislongros = "https://chrislongros.r-universe.dev",CRAN = "https://cloud.r-project.org"))# Install ankiRinstall.packages("ankiR")Key Features
- Read Anki databases: Access your collection.anki2 file or unpack .apkg exports
- Extract review history: Analyze your complete review log (revlog table)
- Access cards and notes: Work with your flashcard content programmatically
- Deck analysis: Examine deck structures and configurations
- Model inspection: Understand your note types and templates
Quick Start Example
Here’s how easy it is to start exploring your Anki data:
library(ankiR)# Connect to your Anki collection# (Find it at ~/.local/share/Anki2/User 1/collection.anki2 on Linux)conn <- read_anki("path/to/collection.anki2")# Get your review historyreviews <- get_revlog(conn)# Analyze review patternslibrary(ggplot2)ggplot(reviews, aes(x = as.Date(as.POSIXct(id/1000, origin = "1970-01-01")))) +geom_histogram(binwidth = 1) +labs(title = "Daily Review Activity",x = "Date",y = "Number of Reviews")# Don't forget to close the connectionclose_anki(conn)Why Analyze Your Anki Data?
Understanding your learning patterns can help you:
- Optimize study habits: Identify your most productive review times
- Track progress: Visualize your learning journey over weeks, months, or years
- Identify problem areas: Find cards or decks with high lapse rates
- Research: Contribute to the growing body of spaced repetition research
- Build custom tools: Create personalized dashboards and reports
Understanding Anki’s Database Structure
For those curious about what’s under the hood, Anki stores data in several tables:
- notes: Your actual flashcard content (fields, tags)
- cards: Individual review items generated from notes
- revlog: Complete history of every review you’ve ever done
- col: Collection metadata, deck configurations, and models
ankiR abstracts away the complexity of parsing JSON-encoded columns and timestamp conversions, giving you clean data frames ready for analysis.
Links and Resources
- CRAN: https://cran.r-project.org/web/packages/ankiR/
- R-universe: https://chrislongros.r-universe.dev/ankiR
- Bug reports: Feel free to open issues on the package repository
Related Projects
If you’re interested in spaced repetition and R, you might also want to check out:
- FSRS: The Free Spaced Repetition Scheduler algorithm, which Anki now supports natively
- anki-snapshot: Git-based version control for Anki collections
Conclusion
Your Anki reviews represent countless hours of deliberate practice. With ankiR, you can finally extract meaningful insights from that data. Whether you’re a medical student tracking board exam prep, a language learner monitoring vocabulary acquisition, or a researcher studying memory, ankiR gives you the tools to understand your learning at a deeper level.
Give it a try, and let me know what insights you discover in your own data!
ankiR is open source and contributions are welcome. Happy learning!
-
As someone who uses Anki extensively for medical studies, I’ve always been fascinated by the algorithms that power spaced repetition. When the FSRS (Free Spaced Repetition Scheduler) algorithm emerged as a more accurate alternative to Anki’s traditional SM-2, I wanted to bring its power to the R ecosystem for research and analysis.
The result is rfsrs — R bindings for the fsrs-rs Rust library, now available on r-universe.
Install it now:
install.packages("rfsrs", repos = "https://chrislongros.r-universe.dev")What is FSRS?
FSRS is a modern spaced repetition algorithm developed by Jarrett Ye that models memory more accurately than traditional algorithms. It’s based on the DSR (Difficulty, Stability, Retrievability) model of memory:
- Stability — How long a memory will last (in days) before dropping to 90% retrievability
- Difficulty — How hard the material is to learn (affects stability growth)
- Retrievability — The probability of recalling the memory at any given time
FSRS-6, the latest version, uses 21 optimizable parameters that can be trained on your personal review history to predict optimal review intervals with remarkable accuracy.
The Rating Scale
FSRS uses a simple 4-point rating scale after each review:
1AgainBlackout2HardStruggled3GoodCorrect4EasyEffortlessWhy Rust + R?
The reference implementation of FSRS is written in Rust (fsrs-rs), which provides excellent performance and memory safety. Rather than rewriting the algorithm in R, I used rextendr to create native R bindings to the Rust library.
This approach offers several advantages:
- Performance — Native Rust speed for computationally intensive operations
- Correctness — Uses the official, well-tested implementation
- Maintainability — Updates to fsrs-rs can be easily incorporated
- Type Safety — Rust’s compiler catches errors at build time
Architecture
Here’s how rfsrs connects R to the Rust library:
rfsrs ArchitectureR Layerfsrs_default_parameters() fsrs_initial_state() fsrs_next_state() fsrs_retrievability()▼rextendr BridgeR → RustVectors → Vec, Lists → structsRust → Rf64 → numeric, structs → lists▼Rust Layer (fsrs-rs)AlgorithmFSRS-6, 21 paramsMemoryStatestability, difficultyFunctionsnext_states(), etc.Usage Examples
Getting Started
library(rfsrs) # Get the 21 default FSRS-6 parameters params <- fsrs_default_parameters() # Create initial memory state (rating: Good) state <- fsrs_initial_state(rating = 3) # $stability: 2.3065 # $difficulty: 2.118104Tracking Memory Decay
# How well will you remember? for (days in c(1, 7, 30, 90)) { r <- fsrs_retrievability(state$stability, days) cat(sprintf("Day %2d: %.1f%%\n", days, r * 100)) } # Day 1: 95.3% # Day 7: 76.4% # Day 30: 49.7% # Day 90: 26.5%Note: Stability of 2.3 days means memory drops to 90% retrievability after 2.3 days. This increases with each successful review.Use Cases for R
- Research — Analyze spaced repetition data with R’s statistical tools
- Visualization — Plot memory decay curves with ggplot2
- Integration with ankiR — Combine with ankiR to analyze your Anki collection
- Custom schedulers — Build spaced repetition apps in R/Shiny
Building Rust + R Packages
The rextendr workflow:
- Create package with
usethis::create_package() - Run
rextendr::use_extendr() - Write Rust with
#[extendr]macros - Run
rextendr::document() - Build and check
Windows builds: Cross-compiling Rust for Windows can be tricky. My r-universe builds work on Linux and macOS but fail on Windows. Windows users can install from source with Rust installed.Resources
- rfsrs on r-universe
- rfsrs on GitHub
- fsrs-rs — The Rust library
- ABC of FSRS — Algorithm intro
- rextendr — R + Rust bindings
What’s Next
Future plans include parameter optimization (training on your review history), batch processing, and tighter ankiR integration.
If you’re interested in spaced repetition or memory research, give rfsrs a try. Feedback welcome!
-
I’ve released anki-snapshot, a tool that brings proper version control to your Anki flashcard collection. Every change to your notes is tracked in git, giving you full history, searchable diffs, and the ability to see exactly what changed and when.
The Problem
Anki’s built-in backup system saves complete snapshots of your database, but it doesn’t tell you what changed. If you accidentally delete a note, modify a card incorrectly, or want to see how your deck evolved over time, you’re stuck comparing opaque database files.
The Solution
anki-snapshot exports your Anki collection to human-readable text files and commits them to a git repository. This means you get:
- Full history: See every change ever made to your collection
- Meaningful diffs: View exactly which notes were added, modified, or deleted
- Search through time: Find when a specific term appeared or disappeared
- Easy recovery: Restore individual notes from any point in history
How It Works
The tool reads your Anki SQLite database and exports notes and cards to pipe-delimited text files. These files are tracked in git, so each time you run
anki-snapshot, any changes are committed with a timestamp.~/anki-snapshot/ ├── .git/ ├── notes.txt # All notes: id|model|fields... ├── cards.txt # All cards: id|note_id|deck|type|queue|due|ivl... └── decks.txt # Deck information
Commands
Command Description anki-snapshotExport current state and commit to git anki-diffShow changes since last snapshot anki-logShow commit history with stats anki-search "term"Search current notes for a term anki-search "term" --historySearch through all git history anki-restore <commit> <note_id>Restore a specific note from history Example: Tracking Changes
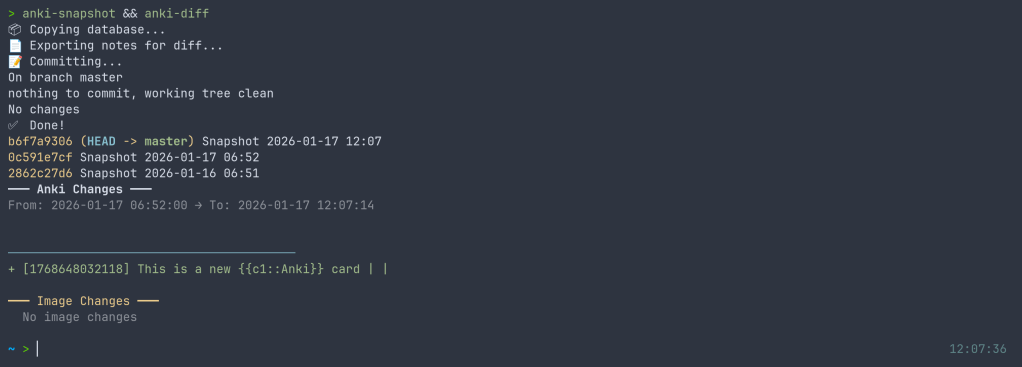
After editing some cards in Anki, run the snapshot and see what changed:
$ anki-snapshot [main a3f2b1c] Snapshot 2026-01-14 21:30:45 1 file changed, 3 insertions(+), 1 deletion(-) $ anki-diff ━━━ Changes since last snapshot ━━━ Modified notes: 2 + [1462223862805] Which antibodies are associated with Hashimoto... − [1462223862805] Which antibodies are associated with Hashimoto... New notes: 1 + [1767170915030] Germline polymorphisms of the ATPase 6 gene...
Example: Searching History
Find when “mitochondria” was added or modified across your entire collection history:
$ anki-search "mitochondria" --history commit e183cea7b3e36ad8b8faf7ca9d5eb8ca44d5bb5e Date: Tue Jan 13 22:43:47 2026 +0100 + [1469146863262] If a disease has a mitochondrial inheritance pattern... + [1469146878242] Mitochondrial diseases often demonstrate variable expression... commit 41c25a53471fc72a520d2683bd3defd6c0d92a88 Date: Tue Jan 13 22:34:48 2026 +0100 − [1469146863262] If a disease has a mitochondrial inheritance pattern...
Integration with Anki
For seamless integration, you can hook the snapshot into your Anki workflow. I use a wrapper script that runs the snapshot automatically when closing Anki:
$ anki-wrapper # Opens Anki, snapshots on close
Or add it to your shell aliases to run before building/syncing your deck.
Installation
The tool is available on the AUR for Arch Linux users:
yay -S anki-snapshot
Or install manually:
git clone https://github.com/chrislongros/anki-snapshot-tool cd anki-snapshot-tool ./install.sh
Requires: bash, git, sqlite3
Why Not Just Use Anki’s Backups?
Anki’s backups are great for disaster recovery, but they’re binary blobs. You can’t:
- See what changed between two backups without restoring them
- Search for when specific content was added
- Selectively restore individual notes
- Track your collection’s evolution over months or years
With git-based snapshots, your entire editing history becomes searchable, diffable, and recoverable.
Screenshot:
Source Code
-
I’ve just released fsrsr, an R package that provides bindings to fsrs-rs, the Rust implementation of the Free Spaced Repetition Scheduler (FSRS) algorithm. This means you can now use the state-of-the-art spaced repetition algorithm directly in R without the maintenance burden of a native implementation.
What is FSRS?
FSRS is a modern spaced repetition algorithm that outperforms traditional algorithms like SM-2 (used in Anki’s default scheduler). It uses a model based on the DSR (Difficulty, Stability, Retrievability) framework to predict memory states and optimize review intervals for long-term retention.
Why Bindings Instead of Native R?
Writing and maintaining a native R implementation of FSRS would be challenging:
- The algorithm involves complex mathematical models that evolve with research
- Performance matters when scheduling thousands of cards
- Keeping pace with upstream changes requires ongoing effort
By using extendr to create Rust bindings, we get:
- Automatic updates: Just bump the fsrs-rs version to get algorithm improvements
- Native performance: Rust’s speed with R’s convenience
- Battle-tested code: The same implementation used by Anki and other major apps
Installation
You’ll need Rust installed (rustup.rs), then:
remotes::install_github("chrislongros/fsrsr")Basic Usage
Here’s a simple example showing the core workflow:
library(fsrsr) # Initialize a new card with a "Good" rating (3) state <- fsrs_initial_state(3) # $stability: 3.17 # $difficulty: 5.28 # After reviewing 3 days later with "Good" rating new_state <- fsrs_next_state( stability = state$stability, difficulty = state$difficulty, elapsed_days = 3, rating = 3 ) # Calculate next interval for 90% target retention interval <- fsrs_next_interval(new_state$stability, 0.9) # Returns: days until next review # Check recall probability after 5 days prob <- fsrs_retrievability(new_state$stability, 5) # Returns: 0.946 (94.6% chance of recall)
Available Functions
Function Description fsrs_default_parameters()Get the 21 default FSRS parameters fsrs_initial_state(rating)Initialize memory state for a new card fsrs_next_state(S, D, days, rating)Calculate next memory state after review fsrs_next_interval(S, retention)Get optimal interval for target retention fsrs_retrievability(S, days)Calculate probability of recall Ratings follow Anki’s convention: 1 = Again, 2 = Hard, 3 = Good, 4 = Easy.
Use Cases
- Research: Analyze spaced repetition data using R’s statistical tools
- Custom SRS apps: Build R Shiny applications with proper scheduling
- Simulation: Model learning outcomes under different review strategies
- Data analysis: Process Anki export data with accurate FSRS calculations
Technical Details
The package uses extendr to generate R bindings from Rust code. The actual FSRS calculations happen in Rust via the fsrs-rs library (v2.0.4), with results passed back to R as native types.
Source code: github.com/chrislongros/fsrsr
-
I recently ran into a performance issue on my TrueNAS SCALE 25.10.1 system where the server felt sluggish despite low CPU usage. The system was running Docker-based applications, and at first glance nothing obvious looked wrong. The real problem turned out to be high iowait.
What iowait actually means
In Linux,
iowaitrepresents the percentage of time the CPU is idle while waiting for I/O operations (usually disk). High iowait doesn’t mean the CPU is busy — it means the CPU is stuck waiting on storage.In
top, this appears aswa:%Cpu(s): 1.8 us, 1.7 sy, 0.0 ni, 95.5 id, 0.2 wa, 0.0 hi, 0.8 si, 0.0 stUnder normal conditions, iowait should stay very low (usually under 1–2%). When it starts climbing higher, the system can feel slow even if CPU usage looks fine.
Confirming the issue with iostat
To get a clearer picture, I used
iostat, which shows per-disk activity and latency:iostat -x 1This immediately showed the problem. One or more disks had:
- Very high
%util(near or at 100%) - Elevated
awaittimes - Consistent read/write pressure
At that point it was clear the bottleneck was storage I/O, not CPU or memory.
Tracking it down to Docker services
This system runs several Docker-based services. Using
topalongsideiostat, I noticed disk activity drop immediately when certain services were stopped.In particular, high I/O was coming from applications that:
- Continuously read/write large files
- Perform frequent metadata operations
- Maintain large active datasets
Examples included downloaders, media managers, and backup-related containers.
Stopping services to confirm
To confirm the cause, I stopped Docker services one at a time and watched disk metrics:
iostat -x 1Each time a heavy I/O service was stopped, iowait dropped immediately. Once the worst offender was stopped, iowait returned to normal levels and the system became responsive again.
Why the system looked “fine” at first
This was tricky because:
- CPU usage was low
- Memory usage looked reasonable
- The web UI was responsive but sluggish
Without checking
iostat, it would have been easy to misdiagnose this as a CPU or RAM issue.Lessons learned
- High iowait can cripple performance even when CPU is idle
topalone is not enough — useiostat -x- Docker workloads can silently saturate disks
- Stopping services one by one is an effective diagnostic technique
Final takeaway
On TrueNAS SCALE 25.10.1 with Docker, high iowait was the real cause of my performance issues. The fix wasn’t a reboot, more CPU, or more RAM — it was identifying and controlling disk-heavy services.
If your TrueNAS server feels slow but CPU usage looks fine, check iowait and run
iostat. The disk may be the real bottleneck. - Very high
-
What’s Changed
- Helm Chart
- chart: Set admin metrics port to http port by @sheyabernstein in #7936
- fix: Invalid volume mount conditional in filer template by @nichobi in #7992
- S3 API
- Fix S3 list objects marker adjustment for delimiters by @chrislusf in #7938
- fix: directory incorrectly listed as object in S3 ListObjects by @chrislusf in #7939
- Refine Bucket Size Metrics: Logical and Physical Size by @chrislusf in #7943
- Fix AWS SDK Signature V4 with STS credentials (issue #7941) by @chrislusf in #7944
- fix: correcting S3 nil cipher dereference in filer init by @tjasko in #7952
- Support AWS standard IAM role ARN formats (issue #7946) by @chrislusf in #7948
- s3api: fix authentication bypass and potential SIGSEGV (Issue #7912) by @chrislusf in #7954
- store S3 storage class in extended atrributes #7961 by @ravenschade in #7962
- fix: handle range requests on empty objects (size=0) by @chrislusf in #7963
- Fix trust policy wildcard principal handling by @chrislusf in #7970
- Support Policy Attachment for Object Store Users by @chrislusf in #7981
- Fix STS identity authorization by populating PolicyNames (#7985) by @chrislusf in #7986
- Fix: ListObjectVersions delimiter support by @chrislusf in #7987
- Fix STS authorization in streaming/chunked uploads by @chrislusf in #7988
- fix(s3api): ensure S3 configuration persistence and refactor authorization tests by @chrislusf in #7989
- Misc
- Standardize -ip.bind flags to default to empty and fall back to -ip by @chrislusf in #7945
- Fix unaligned 64-bit atomic operation on ARM32 (#7958) by @aimmac23 in #7959
- Fix flaky EC integration tests by collecting server logs on failure by @chrislusf in #7969
- test: fix EC integration test needle blob mismatch by @chrislusf in #7972
- chore: execute goimports to format the code by @promalert in #7983
- Filer
- fix(gcs): resolve credential conflict and improve backup logging by @chrislusf in #7951
- Fix jwt error in Filer pod (k8s) by @MorezMartin in #7960
- Fix chown Input/output error on large file sets by @chrislusf in #7996
- Admin
- fix: EC UI template error when viewing shard details by @chrislusf in #7955
- Fix special characters in admin-generated secret keys by @chrislusf in #7994
- FUSE Mount
- Fix: prevent panic when swap file creation fails by @LeeXN in #7957
- Enable writeback_cache and async_dio FUSE options by @chrislusf in #7980
- Mini
- feat: add flags to disable WebDAV and Admin UI in weed mini by @chrislusf in #7971
- Volume Server
- storage/needle: add bounds check for WriteNeedleBlob buffer by @chrislusf in #7973
- opt: reduce ShardsInfo memory usage with bitmap and sorted slice by @chrislusf in #7974
- Helm Chart
-
A journey through packaging Python libraries for spaced repetition and Anki deck generation across multiple platforms.
As someone passionate about both medical education tools and open-source software, I recently embarked on a project to make several useful Python libraries available as native packages for FreeBSD and Arch Linux. This post documents the process and shares what I learned along the way.
The Motivation
Spaced repetition software like Anki has become indispensable for medical students and lifelong learners. However, the ecosystem of tools around Anki—libraries for generating decks programmatically, analyzing study data, and implementing scheduling algorithms—often requires manual installation via pip. This creates friction for users and doesn’t integrate well with system package managers.
My goal was to package three key Python libraries:
- genanki – A library for programmatically generating Anki decks
- fsrs – The Free Spaced Repetition Scheduler algorithm (used in Anki and other SRS apps)
- ankipandas – A library for analyzing Anki collections using pandas DataFrames
Arch Linux User Repository (AUR)
The AUR is a community-driven repository for Arch Linux users. Creating packages here involves writing a
PKGBUILDfile that describes how to fetch, build, and install the software.python-fsrs 6.3.0
The FSRS (Free Spaced Repetition Scheduler) algorithm represents the cutting edge of spaced repetition research. Version 6.x brought significant API changes, including renaming the main
FSRSclass toScheduler.# PKGBUILD for python-fsrs pkgname=python-fsrs pkgver=6.3.0 pkgrel=1 pkgdesc="Free Spaced Repetition Scheduler algorithm" arch=('any') url="https://github.com/open-spaced-repetition/py-fsrs" license=('MIT') depends=('python' 'python-typing_extensions') makedepends=('python-build' 'python-installer' 'python-wheel' 'python-setuptools') source=("https://files.pythonhosted.org/packages/source/f/fsrs/fsrs-${pkgver}.tar.gz") sha256sums=('3abbafd66469ebf58d35a5d5bb693a492e1db44232e09aa8e4d731bf047cd0ae') build() { cd "fsrs-$pkgver" python -m build --wheel --no-isolation } package() { cd "fsrs-$pkgver" python -m installer --destdir="$pkgdir" dist/*.whl install -Dm644 LICENSE "$pkgdir/usr/share/licenses/$pkgname/LICENSE" }The package is now available at: aur.archlinux.org/packages/python-fsrs
python-genanki 0.13.1
genanki allows developers to create Anki decks programmatically—perfect for generating flashcards from databases, APIs, or other structured data sources.
Package available at: aur.archlinux.org/packages/python-genanki
python-ankipandas 0.3.15
ankipandas provides a pandas-based interface for reading and analyzing Anki collection databases, enabling data science workflows on your study data.
Package available at: aur.archlinux.org/packages/python-ankipandas
FreeBSD Ports Collection
FreeBSD’s ports system is more formal than the AUR, with stricter guidelines and a review process. Ports are submitted via Bugzilla and reviewed by committers before inclusion in the official ports tree.
py-genanki Port
Creating a FreeBSD port required several steps:
- Setting up the port skeleton – Creating the Makefile, pkg-descr, and distinfo files
- Handling dependencies – Mapping Python dependencies to existing FreeBSD ports
- Patching setup.py – Removing the
pytest-runnerbuild dependency which doesn’t exist in FreeBSD ports - Testing the build – Running
makeandmake installin a FreeBSD environment
The final Makefile:
PORTNAME= genanki PORTVERSION= 0.13.1 CATEGORIES= devel python MASTER_SITES= PYPI PKGNAMEPREFIX= ${PYTHON_PKGNAMEPREFIX} MAINTAINER= chris.longros@gmail.com COMMENT= Library for generating Anki decks WWW= https://github.com/kerrickstaley/genanki LICENSE= MIT LICENSE_FILE= ${WRKSRC}/LICENSE.txt RUN_DEPENDS= ${PYTHON_PKGNAMEPREFIX}cached-property>0:devel/py-cached-property@${PY_FLAVOR} \ ${PYTHON_PKGNAMEPREFIX}chevron>0:textproc/py-chevron@${PY_FLAVOR} \ ${PYTHON_PKGNAMEPREFIX}frozendict>0:devel/py-frozendict@${PY_FLAVOR} \ ${PYTHON_PKGNAMEPREFIX}pystache>0:textproc/py-pystache@${PY_FLAVOR} \ ${PYTHON_PKGNAMEPREFIX}pyyaml>0:devel/py-pyyaml@${PY_FLAVOR} USES= python USE_PYTHON= autoplist distutils .include <bsd.port.mk>One challenge was that genanki’s
setup.pyrequiredpytest-runneras a build dependency, which doesn’t exist in FreeBSD ports. The solution was to create a patch file that removes this requirement:--- setup.py.orig 2026-01-11 15:32:48.887894000 +0100 +++ setup.py 2026-01-11 15:32:51.336128000 +0100 @@ -27,9 +27,6 @@ 'chevron', 'pyyaml', ], - setup_requires=[ - 'pytest-runner', - ], tests_require=[ 'pytest>=6.0.2', ],py-fsrs Port
The FSRS port followed a similar pattern, with its own set of dependencies to map to FreeBSD ports.
Both ports are available in my GitHub repository and have been submitted to FreeBSD Bugzilla for review:
Lessons Learned
Dependency Resolution
One of the biggest challenges in packaging is mapping upstream dependencies to existing packages in the target ecosystem. For FreeBSD, this meant:
- Searching
/usr/portsfor existing Python packages - Understanding the
@${PY_FLAVOR}suffix for Python version flexibility - Discovering hidden dependencies (like
chevron) that weren’t immediately obvious from the package metadata
Build System Quirks
Python packaging has evolved significantly, with projects using various combinations of:
setup.pywith setuptoolspyproject.tomlwith various backends (setuptools, flit, hatch, poetry)- Legacy
setup_requirespatterns that don’t translate well to system packaging
Creating patches to work around these issues is a normal part of the porting process.
Testing Across Platforms
Running a FreeBSD VM (via VirtualBox) proved essential for testing ports before submission. The build process can reveal missing dependencies, incorrect paths, and other issues that only appear in the actual target environment.
Summary
Package Version AUR FreeBSD python-fsrs / py-fsrs 6.3.0 ✅ Published 📝 Submitted python-genanki / py-genanki 0.13.1 ✅ Published 📝 Submitted python-ankipandas 0.3.15 ✅ Published 🔜 Planned Get Involved
If you use these tools on Arch Linux or FreeBSD, I’d love to hear your feedback. And if you’re interested in contributing to open-source packaging:
- AUR: Browse orphaned packages and consider adopting one you use
- FreeBSD: Run
pkg query -e %m=ports@FreeBSD.org %oto find unmaintained ports you have installed
Every package maintained is one less barrier to entry for users who want to use great software without fighting with dependency management.
Published: January 2026
Repository: github.com/chrislongros/freebsd-ports
-
If you use Anki for spaced repetition learning, you’ve probably wondered about your study patterns. How many cards have you reviewed? What’s your retention like? Which cards are giving you trouble?
I built ankiR to make this easy in R.
The Problem
Anki stores everything in a SQLite database, but accessing it requires writing raw SQL queries. Python users have
ankipandas, but R users had nothing—until now.Installation
# From GitHub remotes::install_github("chrislongros/ankiR") # Arch Linux (AUR) yay -S r-ankirBasic Usage
ankiR auto-detects your Anki profile and provides a tidy interface:
library(ankiR) # See available profiles anki_profiles() # Load your data as tibbles notes <- anki_notes() cards <- anki_cards() reviews <- anki_revlog() # Quick stats nrow(notes) # Total notes nrow(cards) # Total cards nrow(reviews) # Total reviews
FSRS Support
The killer feature: ankiR extracts FSRS parameters directly from your collection.
FSRS (Free Spaced Repetition Scheduler) is the modern scheduling algorithm in Anki that calculates optimal review intervals based on your memory patterns.
fsrs_cards <- anki_cards_fsrs()
This gives you:
- stability – memory stability in days (how long until you forget)
- difficulty – card difficulty on a 1-10 scale
- retention – your target retention rate (typically 0.9 = 90%)
- decay – the decay parameter used in calculations
Example: Visualize Your Card Difficulty
library(ankiR) library(dplyr) library(ggplot2) anki_cards_fsrs() |> filter(!is.na(difficulty)) |> ggplot(aes(difficulty)) + geom_histogram(bins = 20, fill = "steelblue") + labs( title = "Card Difficulty Distribution", x = "Difficulty (1-10)", y = "Count" ) + theme_minimal()Example: Stability vs Difficulty
anki_cards_fsrs() |> filter(!is.na(stability)) |> ggplot(aes(difficulty, stability)) + geom_point(alpha = 0.3, color = "steelblue") + scale_y_log10() + labs( title = "Memory Stability vs Card Difficulty", x = "Difficulty", y = "Stability (days, log scale)" ) + theme_minimal()Example: Review History Over Time
anki_revlog() |> count(review_date) |> ggplot(aes(review_date, n)) + geom_line(color = "steelblue") + geom_smooth(method = "loess", se = FALSE, color = "red") + labs( title = "Daily Review History", x = "Date", y = "Reviews" ) + theme_minimal()Calculate Retrievability
You can also calculate the probability of recalling a card after N days:
# What's my retention after 7 days for a card with 30-day stability? fsrs_retrievability(stability = 30, days_since_review = 7) # Returns ~0.93 (93% chance of recall)
Links
I built this because I wanted to analyze my USMLE study data in R. If you find it useful, let me know!
-
If you’re running Arch Linux and trying to build Anki from source, you may have encountered a frustrating build failure related to Python 3.14. Here’s what went wrong and how I fixed it.
The Problem
Arch Linux recently updated to Python 3.14.2 as the system default. When attempting to build Anki from the main branch, the build failed with this error:
error: the configured Python interpreter version (3.14) is newer than PyO3's maximum supported version (3.13) = help: please check if an updated version of PyO3 is available. Current version: 0.23.3
The issue is that Anki depends on
orjson, a fast JSON library written in Rust. This library uses PyO3 for Python bindings, and the bundled version (0.23.3) only supports Python up to 3.13.Why UV_PYTHON and .python-version Didn’t Work
My first attempts involved setting the
UV_PYTHONenvironment variable and creating a.python-versionfile in the repository root. Neither worked because Anki’s build runner wasn’t passing these settings through to uv when creating the virtual environment. The build system kept detecting and using/usr/bin/python3(3.14.2) regardless.The Solution
The fix is to install Python 3.13 via pyenv and put it first in your PATH so it gets detected before the system Python.
First, install pyenv and Python 3.13:
sudo pacman -S pyenv pyenv install 3.13.1
Then, for your build session, prepend Python 3.13 to your PATH:
export PATH="$HOME/.pyenv/versions/3.13.1/bin:$PATH"
Now clean the build directory and rebuild:
cd ~/ankidev/anki rm -rf out ./tools/runopt
The build should now complete successfully, with the virtual environment using Python 3.13.1:
./out/pyenv/bin/python --version Python 3.13.1
Making It Permanent
If you regularly build Anki, add the PATH modification to your shell configuration:
echo 'export PATH="$HOME/.pyenv/versions/3.13.1/bin:$PATH"' >> ~/.bashrc
Alternatively, create a simple wrapper script for building Anki that sets the PATH temporarily.
Conclusion
This is a temporary issue that will resolve itself once orjson updates its bundled PyO3 to a version that supports Python 3.14. Until then, using pyenv to provide Python 3.13 is a clean workaround that doesn’t require downgrading your system Python or breaking other applications.
The Arch Linux philosophy of staying on the bleeding edge occasionally runs into these compatibility gaps with projects that have Rust dependencies—something to keep in mind when building from source.