The second Release Candidate of the upcoming version.

The second Release Candidate of the upcoming version.
OpenZFS continues to evolve as a robust filesystem for everything from IoT devices to supercomputing clusters. The upcoming OpenZFS 2.4 release (Nov 2025) focuses on stability, usability, and performance.
zfs rewrite command, project quotas on FreeBSD, ZVOL threading, and morehttps://klarasystems.com/articles/zfs-new-features-roadmap-innovations/
An initiative of Klara Inc to launch a Webinar with the most experienced devs in the ZFS storage industry.
Major features include:
special_small_blocks to land ZVOL writes on special vdevs (#14876), and allow non-power of two values (#17497)zfs rewrite -P which preserves logical birth time when possible to minimize incremental stream size (#17565)-a|--all option which scrubs, trims, or initializes all imported pools (#17524)zpool scrub -S -E to scrub specific time ranges (#16853)This feature will allow the maximal use of storage in a ZFS pool consisted by drives of different capacity.
https://hexos.com/blog/introducing-zfs-anyraid-sponsored-by-eshtek

“Key Features in OpenZFS 2.3.0:
RAIDZ Expansion (#15022): Add new devices to an existing RAIDZ pool, increasing storage capacity without downtime.
Fast Dedup (#15896): A major performance upgrade to the original OpenZFS deduplication functionality.
Direct IO (#10018): Allows bypassing the ARC for reads/writes, improving performance in scenarios like NVMe devices where caching may hinder efficiency.
JSON (#16217): Optional JSON output for the most used commands.
Long names (#15921): Support for file and directory names up to 1023 characters.
Bug Fixes: A series of critical bug fixes addressing issues reported in previous versions.
Numerous performance improvements throughout the code base.
Supported Platforms:
Linux kernels 4.18 - 6.12,
FreeBSD releases 13.3, 14.0 - 14.2.
1041 commits and 999 changed files

433 FreeBSD commits and 175 contributions to my favorite filesystem ZFS💪🏾

In Portland, Oregon.
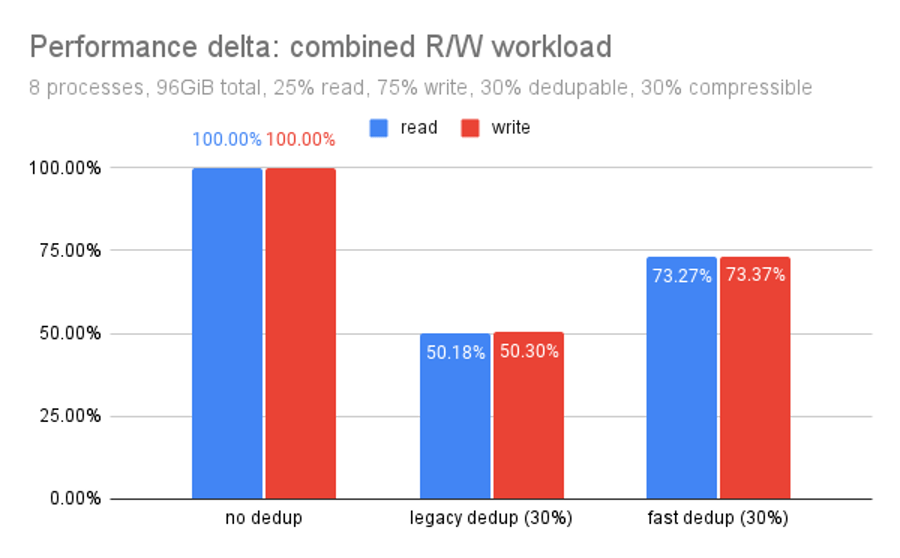
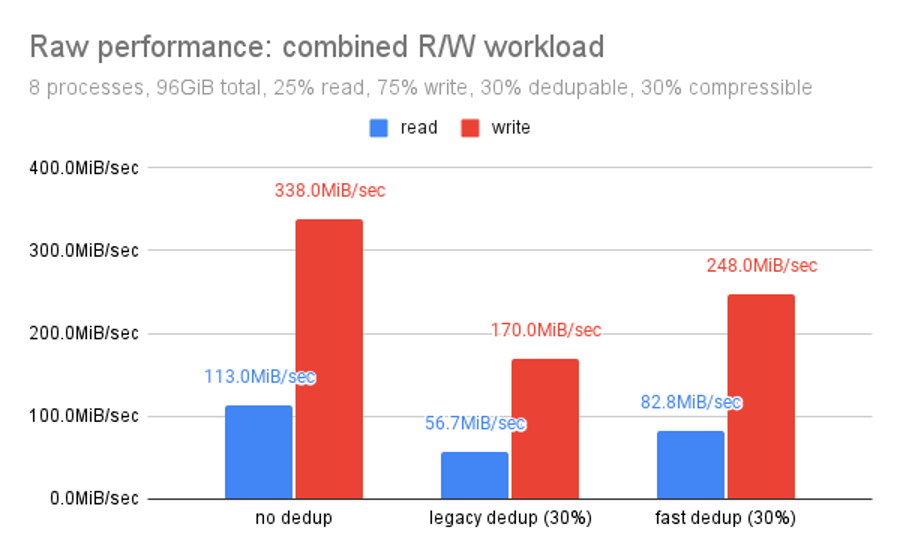
“Performance delta focuses on the relationship of each dedup routine compared to un-deduped storage on the same hardware. It’s the same data but organized differently.
Fast dedup outperforms legacy dedup by almost 25% of the raw performance.“