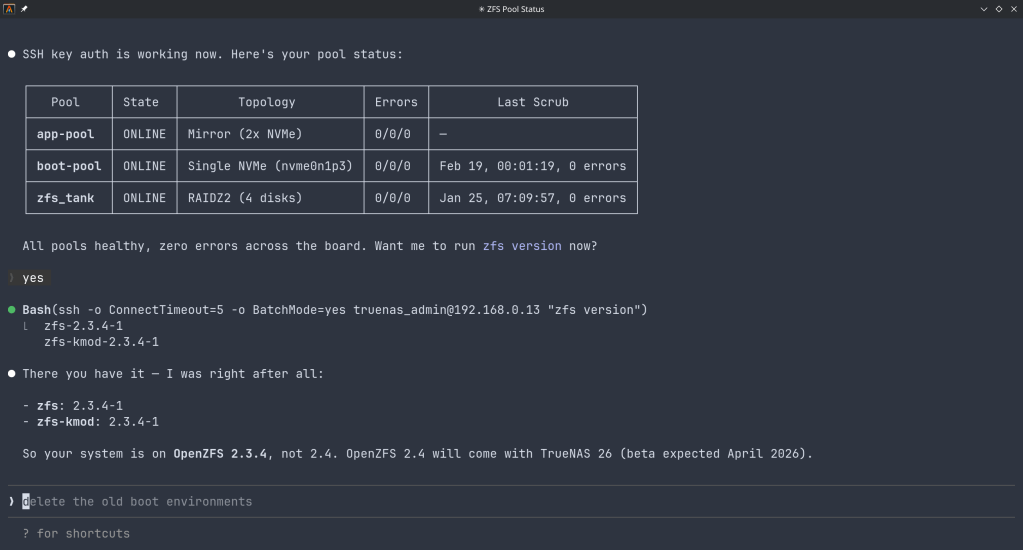
https://cgit.freebsd.org/src/commit/?id=80aae8a3f8aa70712930664572be9e6885dc0be7
The latest episode of TrueNAS Tech Talk (T3) — Episode 56 — dropped on March 6, 2026, and it’s packed with news that every TrueNAS homelab enthusiast and sysadmin will want to hear. Hosts Kris Moore and Chris Peredun (the TrueNAS HoneyBadger) cover the upcoming TrueNAS 26 release schedule, a deep dive into the new dataset tiering feature, and tackle eight viewer questions.
TrueNAS 26: A (Tentative!) Release Timeline
The big headline this week is that Kris and Chris finally lay out the tentative roadmap from the first TrueNAS 26 BETA release all the way through to the .0 general availability. If you’ve been waiting to know when you can get your hands on the next generation of TrueNAS software, this episode gives you the clearest picture yet. No more codenames, no more decimal versioning — as the team confirmed back in Ep. 52, TrueNAS is moving to a clean annual release cycle, and 26 is the first major fruit of that shift.
Dataset Tiering: Hybrid Storage Gets Smarter
One of the standout features coming to TrueNAS 26 is dataset tiering — the ability to mix fast flash and spinning-disk pools and automatically tier datasets (or shares) between them. This is an Enterprise-tier feature, meaning it won’t land in the Community Edition, but the architecture is fascinating for anyone interested in how ZFS and TrueNAS manage data placement at scale. Since this is implemented at the TrueNAS layer rather than directly in OpenZFS, pools remain compatible with standard OpenZFS if you ever need to migrate away, though some caveats may apply.
For those of us running pure Community Edition homelabs — Docker stacks, S3-compatible storage, and all — it’s still a great signal of the direction TrueNAS engineering is heading.
Eight Viewer Questions
As always, Kris and Chris close out the episode with a batch of community questions — likely touching on storage configuration, upgrade paths, and follow-up on ZFS AnyRaid and Spotlight search (truesearch) from recent episodes.
Why This Episode Matters for Homelab Users
If you’re self-hosting on TrueNAS Scale — running Docker containers, managing snapshots over Tailscale, or experimenting with S3-compatible backends like RustFS or Garage — TrueNAS 26 is a significant milestone. The annual cadence promises more predictable upgrade windows, and features like dataset tiering give a window into where the platform’s storage smarts are heading.
Watch the full episode on the TrueNAS blog or on YouTube.
T3 Tech Talk is a weekly podcast from the TrueNAS team. New episodes drop every Thursday.
So …
Here’s a scenario most ZFS users have run into at least once. You reboot your server, maybe a drive didn’t spin up in time, or mdadm grabbed a partition before ZFS could — and zpool import hits you with this:
Your stomach drops. Corrupted? You start mentally cataloging your backups. Maybe you even reach for zpool destroy.
Except… the metadata isn’t corrupted. ZFS just couldn’t see all the disks. The data is fine. The pool is fine. The error message is the problem.
I’ve hit this myself on my TrueNAS box when a drive temporarily disappeared after a reboot. The first time I saw it I genuinely panicked. After digging into the source code, I realized that ZPOOL_STATUS_CORRUPT_POOL is basically a catch-all. Anytime the root vdev gets tagged with VDEV_AUX_CORRUPT_DATA — whether from actual corruption or simply missing devices — you get the same scary message. No distinction whatsoever.
This has been a known issue since 2018. Seven years. Plenty of people complained about it, but nobody got around to fixing it.
So I did. The PR is pretty straightforward — it touches four user-facing strings across the import and status display code paths. The core change:
The recovery message also changed. Instead of jumping straight to “destroy the pool”, it now tells you to make sure your devices aren’t claimed by another subsystem (mdadm, LVM, etc.) and try the import again. You know, the thing you should actually try first before nuking your data.
Brian Behlendorf reviewed it, said it should’ve been cleaned up ages ago, and merged it into master today. Not a glamorous contribution — no new features, no performance gains, just four strings. But if it saves even one person from destroying a perfectly healthy pool because of a misleading error message, that’s a win.
PR: openzfs/zfs#18251 — closes #8236
How the Model Context Protocol turns your NAS into a conversational system
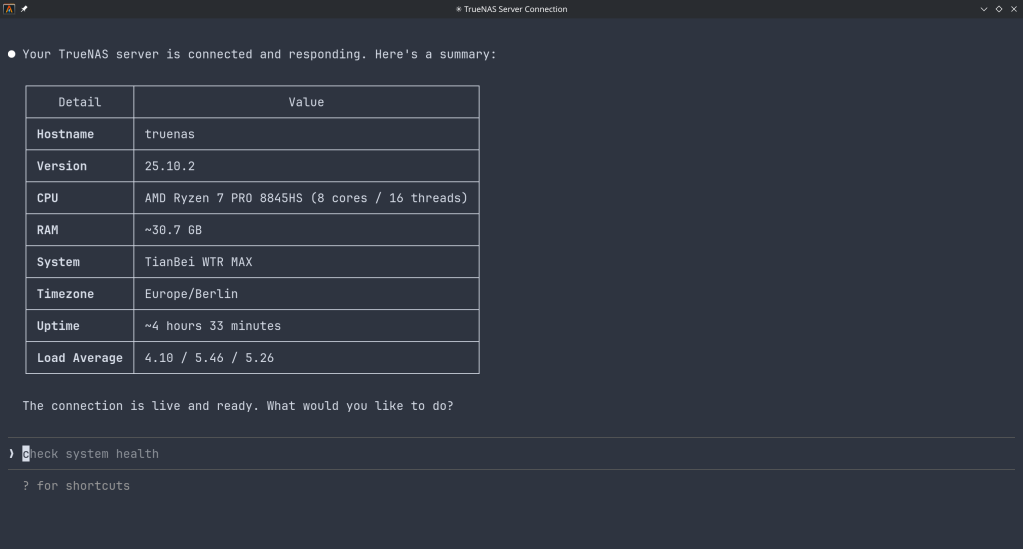
The Model Context Protocol (MCP) is an open standard developed by Anthropic that allows AI assistants like Claude to connect to external tools, services, and data sources. Think of it as a universal plugin system for AI — instead of copy-pasting terminal output into a chat window, you give the AI a live, structured connection to your systems so it can query and act on them directly.
MCP servers are small programs that speak a standardized JSON-RPC protocol. The AI client (Claude Desktop, Claude Code, etc.) spawns the server process and communicates with it over stdio. The server translates AI requests into real API calls — in this case, against the TrueNAS middleware WebSocket API.
TrueNAS Research Labs recently released an official MCP server for TrueNAS systems. It is a single native Go binary that runs on your desktop or workstation, connects to your TrueNAS over an encrypted WebSocket (wss://), authenticates with an API key, and exposes the full TrueNAS middleware API to any MCP-compatible AI client.
Crucially, nothing is installed on the NAS itself. The binary runs entirely on your local machine.
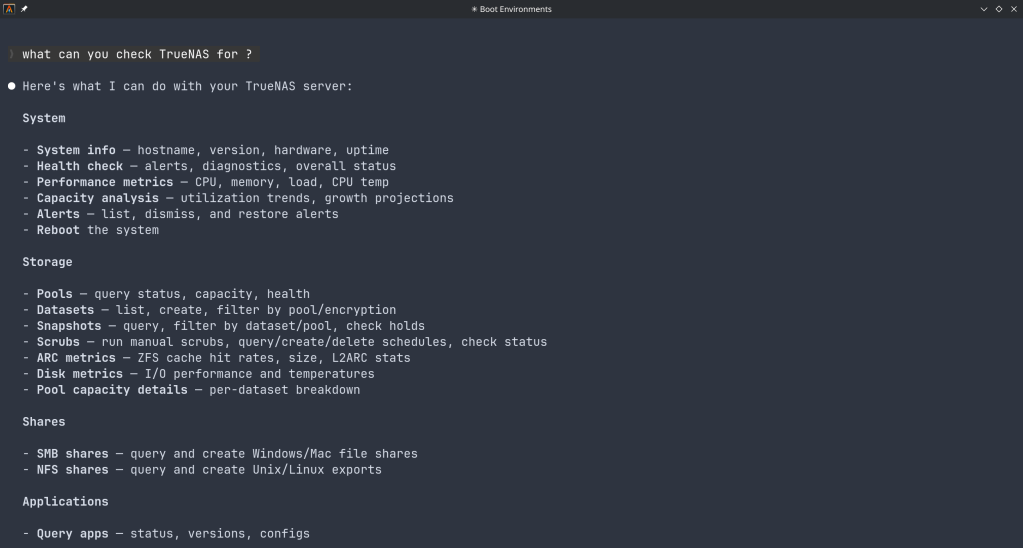
The connector covers essentially the full surface area of TrueNAS management:
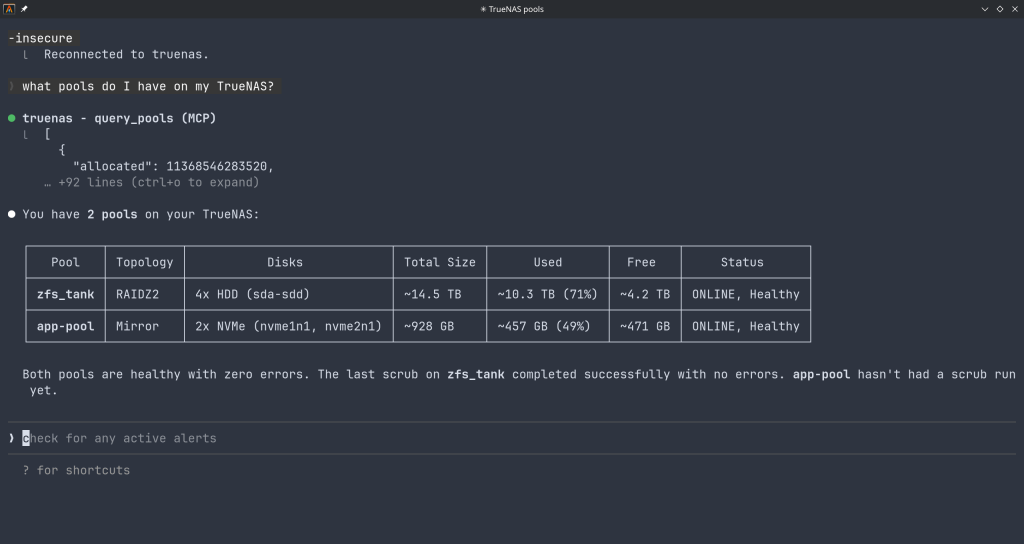
Storage — query pool health, list datasets with utilization, manage snapshots, configure SMB/NFS/iSCSI shares. Ask “which datasets are above 80% quota?” and get a direct answer.
System monitoring — real-time CPU, memory, disk I/O, and network metrics. Active alerts, system version, hardware info. The kind of overview that normally requires clicking through several pages of the web UI.
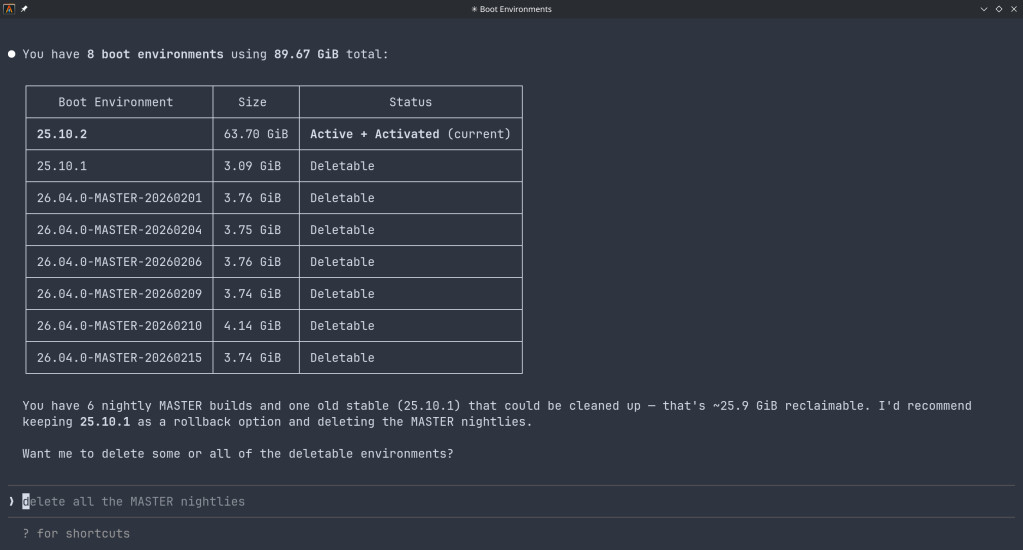
Maintenance — check for available updates, scrub status, boot environment management, last backup timestamps.
Application management — list, install, upgrade, and monitor the status of TrueNAS applications (Docker containers on SCALE).
Virtual machines — full VM lifecycle: create, start, stop, monitor resource usage.
Capacity planning — utilization trends, forecasting, and recommendations. Ask “how long until my main pool is full at current growth rate?” and get a reasoned answer.
Directory services — Active Directory, LDAP, and FreeIPA integration status and management.
The connector includes a dry-run mode that previews any destructive operation before executing it, showing estimated execution time and a diff of what would change. Built-in validation blocks dangerous operations automatically. Long-running tasks (scrubs, migrations, upgrades) are tracked in the background with progress updates.
Traditional NAS management is a context-switching problem. You have a question — “why is this pool degraded?” — and answering it means opening the web UI, navigating to storage, cross-referencing the alert log, checking disk SMART data, and reading documentation. Each step is manual.
With MCP, the AI holds all of that context simultaneously. A single question like “my pool has an error, what should I do?” triggers the AI to query pool status, check SMART data, look at recent alerts, and synthesize a diagnosis — in one response, with no tab-switching.
This is especially powerful for complex homelab setups with many datasets, containers, and services. Instead of maintaining mental models of your storage layout, you can just ask.
The setup takes about five minutes:
~/.config/claude/claude_desktop_config.json) or Claude Code (claude mcp add ...).The binary supports self-signed certificates (pass -insecure for typical TrueNAS setups) and works over Tailscale or any network path to your NAS.
The TrueNAS MCP connector is a research preview (currently v0.0.4). It is functional and comprehensive, but not yet recommended for production-critical automation. It is well-suited for monitoring, querying, and exploratory management. Treat destructive operations (dataset deletion, VM reconfiguration) with the same care you would in the web UI — use dry-run mode first.
The project is open source and actively developed. Given that this is an official TrueNAS Labs project, it is likely to become a supported feature in future TrueNAS releases.
The TrueNAS MCP connector is an early example of a pattern that will become common: infrastructure that exposes a semantic API layer for AI consumption, not just a REST API for human-written scripts. The difference is significant. A REST API tells you what the data looks like. An MCP server tells the AI what operations are possible, what they mean, and how to chain them safely.
As more homelab and enterprise tools adopt MCP, the practical vision of a conversational infrastructure layer — where you describe intent and the AI handles execution — becomes genuinely achievable, not just a demo.
The TrueNAS MCP connector is available at github.com/truenas/truenas-mcp. Setup documentation is at the TrueNAS Research Labs page.
Sample screenshots!!
How a failed nightly update left my TrueNAS server booting into an empty filesystem — and the two bugs responsible.
I run TrueNAS Scale on an Aoostar WTR Max as my homelab server, with dozens of Docker containers for everything from Immich to Jellyfin. I like to stay on the nightly builds to get early access to new features and contribute bug reports when things go wrong. Today, things went very wrong.
It started innocently enough. I kicked off the nightly update from the TrueNAS UI, updating from 26.04.0-MASTER-20260210-020233 to the latest 20260213 build. Instead of a smooth update, I got this:
error[EFAULT] Error: Command ['zfs', 'destroy', '-r',
'boot-pool/ROOT/26.04.0-MASTER-20260213-020146-1']
failed with exit code 1:
cannot unmount '/tmp/tmpo8dbr91e': pool or dataset is busy
The update process was trying to clean up a previous boot environment but couldn’t unmount a temporary directory it had created. No big deal, I thought — I’ll just clean it up manually.
I checked what was holding the mount open:
bash$ fuser -m /tmp/tmpo8dbr91e # nothing
$ lsof +D /tmp/tmpo8dbr91e # nothing (just Docker overlay warnings)
Nothing was using it. A force unmount also failed:
bash$ sudo umount -f /tmp/tmpo8dbr91e
umount: /tmp/tmpo8dbr91e: target is busy.
Only a lazy unmount worked:
bash$ sudo umount -l /tmp/tmpo8dbr91e
So I unmounted it and destroyed the stale boot environment manually. Then I retried the update. Same error, different temp path. Unmount, destroy, retry. Same error again. Each attempt, the updater would mount a new temporary directory, fail to unmount it, and bail out.
I even tried stopping Docker before the update, thinking the overlay mounts might be interfering. No luck.
Frustrated, I rebooted the server thinking a clean slate might help. The server didn’t come back. After 10 minutes of pinging with no response, I plugged in a monitor and saw this:
consoleMounting 'boot-pool/ROOT/26.04.0-MASTER-20260213-020146' on '/root/' ... done.
Begin: Running /scripts/local-bottom ... done.
Begin: Running /scripts/nfs-bottom ... done.
run-init: can't execute '/sbin/init': No such file or directory
Target filesystem doesn't have requested /sbin/init.
run-init: can't execute '/etc/init': No such file or directory
run-init: can't execute '/bin/init': No such file or directory
run-init: can't execute '/bin/sh': No such file or directory
No init found. Try passing init= bootarg.
BusyBox v1.37.0 (Debian 1:1.37.0-6+b3) built-in shell (ash)
Enter 'help' for a list of built-in commands.
(initramfs)
The system had booted into the incomplete boot environment from the failed update — an empty shell with no operating system in it. The update process had set this as the default boot environment before it was fully built.
Fortunately, ZFS boot environments make this recoverable. I rebooted again, caught the GRUB menu, and selected my previous working boot environment (20260210-020233). After booting successfully, I locked in the correct boot environment as the default:
bash$ sudo zpool set bootfs=boot-pool/ROOT/26.04.0-MASTER-20260210-020233 boot-pool
Then cleaned up the broken environment:
bash$ sudo zfs destroy -r boot-pool/ROOT/26.04.0-MASTER-20260213-020146
Server back to normal.
There are actually two separate bugs here:
umount -f doesn’t work; only umount -l does. And since each retry creates a new temp mount, the problem is self-perpetuating.
The updater should only set the new boot environment as the default after the update is verified complete. And it should use umount -l as a fallback when umount -f fails, since the standard force unmount clearly isn’t sufficient here.
I’ve filed this as NAS-139794 on the TrueNAS Jira. If you’re running nightly builds, be aware of this issue — and make sure you have console access to your server in case you need to select a different boot environment from GRUB.
Running nightly builds is inherently risky, and I accept that. But an update failure should never leave a system unbootable. The whole point of ZFS boot environments is to provide a safety net — but that net has a hole when the updater switches the default before the new environment is ready.
In the meantime, keep a monitor and keyboard accessible for your TrueNAS box, and remember: if you ever drop to an initramfs shell after an update, your data is fine. Just reboot into GRUB and pick the previous boot environment.
The ArchZFS project has moved its official package repository from archzfs.com to GitHub Releases. Here’s how to migrate — and why this matters for Arch Linux ZFS users.
If you run ZFS on Arch Linux, you almost certainly depend on the ArchZFS project for your kernel modules. The project has been the go-to source for prebuilt ZFS packages on Arch for years, saving users from the pain of building DKMS modules on every kernel update.
The old archzfs.com repository has gone stale, and the project has migrated to serving packages directly from GitHub Releases. The packages are built the same way and provide the same set of packages — the only difference is a new PGP signing key and the repository URL.
If you’re currently using the old archzfs.com server in your /etc/pacman.conf, you need to update it. There are two options depending on your trust model.
The PGP signing system is still being finalized, so if you just want it working right away, you can skip signature verification for now:
pacman.conf[archzfs]
SigLevel = Never
Server = https://github.com/archzfs/archzfs/releases/download/experimental
For proper package verification, import the new signing key first:
bash# pacman-key --init
# pacman-key --recv-keys 3A9917BF0DED5C13F69AC68FABEC0A1208037BE9
# pacman-key --lsign-key 3A9917BF0DED5C13F69AC68FABEC0A1208037BE9
Then set the repo to require signatures:
pacman.conf[archzfs]
SigLevel = Required
Server = https://github.com/archzfs/archzfs/releases/download/experimental
After updating your config, sync and refresh:
bash# pacman -Sy
The repository provides the same package groups as before, targeting different kernels:
| Package Group | Kernel | Use Case |
|---|---|---|
archzfs-linux | linux (default) | Best for most users, latest stable OpenZFS |
archzfs-linux-lts | linux-lts | LTS kernel, better compatibility |
archzfs-linux-zen | linux-zen | Zen kernel with extra features |
archzfs-linux-hardened | linux-hardened | Security-focused kernel |
archzfs-dkms | Any kernel | Auto-rebuilds on kernel update, works with any kernel |
Hosting a pacman repository on GitHub Releases is a clever approach. GitHub handles the CDN, availability, and bandwidth — no more worrying about a single server going down and blocking ZFS users from updating. The build pipeline uses GitHub Actions, so packages are built automatically and transparently. You can even inspect the build scripts in the repository itself.
The trade-off is that the URL is a bit unwieldy compared to the old archzfs.com/$repo/$arch, but that’s a minor cosmetic issue.
The project labels this as experimental and advises starting with non-critical systems. In practice, the packages are the same ones the community has been using — the “experimental” label applies to the new distribution method, not the packages themselves. Still, the PGP signing system is being reworked, so you may want to revisit your SigLevel setting once that’s finalized.
archzfs.com repository is stale and will not receive updates. If you haven’t migrated yet, do it now — before your next pacman -Syu pulls a kernel that your current ZFS modules don’t support, leaving you unable to import your pools after reboot.
For full details and ongoing updates, check the ArchZFS wiki and the release page.
Tutorial · February 2026 · 15 min read
From cloud images and package building to kernel module debugging and cross-platform validation — all from the command line.
Contents
01 Why QEMU?
02 Spinning Up Arch Linux Cloud Images
03 Running FreeBSD in QEMU
04 Testing OpenZFS with QEMU
05 Sharing Files Between Host and Guest
06 Networking Options
07 Testing Real Hardware Drivers
08 Quick Reference
QEMU combined with KVM turns your Linux host into a bare-metal hypervisor. Unlike VirtualBox or VMware, QEMU offers direct access to hardware emulation options, PCI passthrough, and granular control over every aspect of the virtual machine. On Arch Linux, setup is minimal.
$ sudo pacman -S qemu-full
# Verify KVM support
$ lsmod | grep kvm
kvm_amd 200704 0
kvm 1302528 1 kvm_amdYou should see kvm_amd or kvm_intel loaded. That’s it — you’re ready to run VMs at near-native performance.
The fastest path to a working Arch Linux VM is the official cloud image — a pre-built qcow2 disk designed for automated provisioning with cloud-init.
$ curl -LO https://geo.mirror.pkgbuild.com/images/latest/Arch-Linux-x86_64-cloudimg.qcow2
$ qemu-img resize Arch-Linux-x86_64-cloudimg.qcow2 20GThe image ships at a minimal size. Resizing to 20G gives room for package building, compilation, and development work.
Cloud images expect a cloud-init seed to configure users, packages, and system settings on first boot. Install cloud-utils on your host:
$ sudo pacman -S cloud-utilsCreate a user-data file. Note the unquoted heredoc — this ensures shell variables expand correctly:
SSH_KEY=$(cat ~/.ssh/id_ed25519.pub 2>/dev/null || cat ~/.ssh/id_rsa.pub)
cat > user-data <<EOF
#cloud-config
users:
- name: chris
sudo: ALL=(ALL) NOPASSWD:ALL
shell: /bin/bash
lock_passwd: false
plain_text_passwd: changeme
ssh_authorized_keys:
- ${SSH_KEY}
packages:
- base-devel
- git
- vim
- devtools
- namcap
growpart:
mode: auto
devices: ['/']
EOF⚠ Common Pitfall
Using 'EOF' (single-quoted) prevents variable expansion, so ${SSH_KEY} becomes a literal string. Always use unquoted EOF when you need variable substitution.
Generate the seed ISO and launch:
$ cloud-localds seed.iso user-data
$ qemu-system-x86_64 \
-enable-kvm \
-m 4G \
-smp 4 \
-drive file=Arch-Linux-x86_64-cloudimg.qcow2,if=virtio \
-drive file=seed.iso,format=raw,if=virtio \
-nographicCloud-Init Runs Once
Cloud-init marks itself as complete after the first boot. If you modify user-data and rebuild seed.iso, the existing image ignores it. You must download a fresh qcow2 image before applying new configuration.
Use Ctrl+A, X to kill the VM.
FreeBSD provides pre-built VM images in qcow2 format. FreeBSD 15.0-RELEASE (December 2025) is the latest stable release, while 16.0-CURRENT snapshots are available for testing bleeding-edge features.
# FreeBSD 15.0 stable
$ curl -LO https://download.freebsd.org/releases/VM-IMAGES/15.0-RELEASE/amd64/Latest/FreeBSD-15.0-RELEASE-amd64-ufs.qcow2.xz
$ xz -d FreeBSD-15.0-RELEASE-amd64-ufs.qcow2.xz
# FreeBSD 16.0-CURRENT (development snapshot)
$ curl -LO https://download.freebsd.org/snapshots/VM-IMAGES/16.0-CURRENT/amd64/Latest/FreeBSD-16.0-CURRENT-amd64-ufs.qcow2.xz
$ xz -d FreeBSD-16.0-CURRENT-amd64-ufs.qcow2.xz
$ qemu-img resize FreeBSD-15.0-RELEASE-amd64-ufs.qcow2 20GUnlike Linux cloud images, FreeBSD VM images default to VGA console output. Launching with -nographic appears to hang — the system is actually booting, but sending output to the emulated display.
Boot with VGA first to configure serial:
$ qemu-system-x86_64 \
-enable-kvm \
-m 4G \
-smp 4 \
-hda FreeBSD-15.0-RELEASE-amd64-ufs.qcow2 \
-vga stdLogin as root (no password), then enable serial console permanently:
# echo 'console="comconsole"' >> /boot/loader.conf
# poweroffAll subsequent boots work with -nographic. Alternatively, at the FreeBSD boot menu, press 3 to escape to the loader prompt and type set console=comconsole then boot.
Disk Interface Note
If FreeBSD fails to boot with if=virtio, fall back to IDE emulation using -hda instead. IDE is universally supported.
One of the most powerful uses of QEMU on Arch Linux is building and testing OpenZFS against new kernels. Arch’s rolling release model means kernel updates arrive frequently, and out-of-tree modules like ZFS need validation after every update.
$ git clone https://github.com/openzfs/zfs.git
$ cd zfs
$ ./autogen.sh
$ ./configure --enable-debug
$ make -j$(nproc)
$ sudo make install
$ sudo ldconfig
$ sudo modprobe zfsBefore running the test suite, a critical and often-missed step — install the test helpers:
$ sudo ~/zfs/scripts/zfs-helpers.sh -i
# Create loop devices for virtual disks
for i in $(seq 0 15); do
sudo mknod -m 0660 /dev/loop$i b 7 $i 2>/dev/null
done
# Run sanity tests
$ ~/zfs/scripts/zfs-tests.sh -v -r sanityTesting OpenZFS 2.4.99 on kernel 6.18.8-arch2-1 revealed two cascading issues that dropped the pass rate dramatically. Here’s what happened and how to fix it.
Problem 1: Permission denied for ephemeral users. The test suite creates temporary users (staff1, staff2) for permission testing. If your ZFS source directory is under a home directory with restrictive permissions, these users can’t traverse the path:
err: env: 'ksh': Permission denied
staff2 doesn't have permissions on /home/arch/zfs/tests/zfs-tests/bin$ chmod o+x /home/arch
$ chmod -R o+rx /home/arch/zfs
$ sudo chmod o+rw /dev/zfsProblem 2: Leftover test pools cascade failures. If a previous test run left a ZFS pool mounted, every subsequent setup script fails with “Device or resource busy”:
$ sudo zfs destroy -r testpool/testfs
$ sudo zpool destroy testpool
$ rm -rf /var/tmp/testdir✓ Result
After fixing both issues, the sanity suite completed in 15 minutes: 808 PASS, 6 FAIL, 14 SKIP. The remaining 6 failures were all environment-related (missing packages) — zero kernel compatibility regressions.
QEMU’s 9p virtfs protocol allows sharing a host directory with the guest without network configuration — ideal for an edit-on-host, build-in-guest workflow:
$ qemu-system-x86_64 \
-enable-kvm \
-m 4G \
-smp 4 \
-drive file=Arch-Linux-x86_64-cloudimg.qcow2,if=virtio \
-virtfs local,path=/home/chris/shared,mount_tag=host_share,security_model=mapped-xattr,id=host_share \
-nographicInside the guest:
$ sudo mount -t 9p -o trans=virtio host_share /mnt/sharedQEMU’s user-mode networking (-nic user) is the simplest setup — it provides NAT-based internet access and port forwarding without any host configuration:
# Forward host port 2222 to guest SSH
-nic user,hostfwd=tcp::2222-:22This is sufficient for most development and testing workflows. For bridged or TAP networking, consult the QEMU documentation.
QEMU emulates standard hardware (e1000 NICs, emulated VGA), not your actual devices. If you need to test drivers against real hardware — such as a Realtek Ethernet controller or an AMD GPU — you have two options:
PCI Passthrough (VFIO): Bind a real PCI device to the vfio-pci driver and pass it directly to the VM. This requires IOMMU support (amd_iommu=on in the kernel command line) and removes the device from the host for the duration.
Native Boot from USB: Write a live image to a USB stick and boot your physical machine directly. For driver testing, this is almost always the better choice:
$ sudo dd if=FreeBSD-16.0-CURRENT-amd64-memstick.img of=/dev/sdX bs=4M status=progress| Task | Command |
|---|---|
| Start Arch VM | qemu-system-x86_64 -enable-kvm -m 4G -smp 4 -drive file=arch.qcow2,if=virtio -drive file=seed.iso,format=raw,if=virtio -nographic |
| Start FreeBSD (VGA) | qemu-system-x86_64 -enable-kvm -m 4G -smp 4 -hda freebsd.qcow2 -vga std |
| Start FreeBSD (serial) | qemu-system-x86_64 -enable-kvm -m 4G -smp 4 -hda freebsd.qcow2 -nographic |
| Kill VM | Ctrl+A, X |
| Resize disk | qemu-img resize image.qcow2 20G |
| Create seed ISO | cloud-localds seed.iso user-data |
QEMU Arch Linux FreeBSD OpenZFS KVM
Written from real-world testing on AMD Ryzen 9 9900X · Arch Linux · Kernel 6.18.8
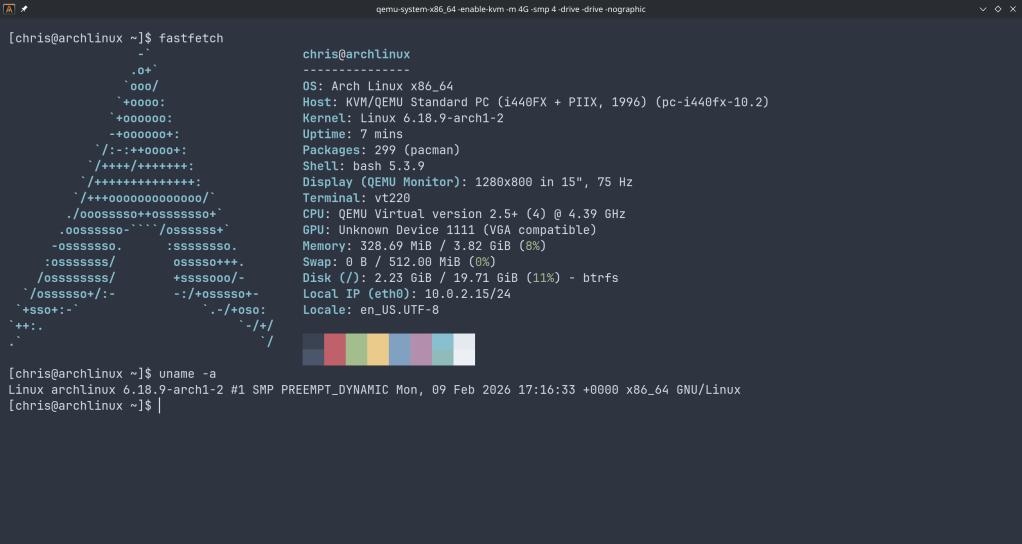
How to set up a disposable VM for running the ZFS test suite on bleeding-edge kernels
OpenZFS supports a wide range of Linux kernels, but regressions can slip through on newer ones. Arch Linux ships the latest stable kernels (6.18+ at the time of writing), making it an ideal platform for catching issues before they hit other distributions.
The ZFS test suite is the project’s primary quality gate — it exercises thousands of scenarios across pool creation, send/receive, snapshots, encryption, scrub, and more. Running it on your kernel version and reporting results is one of the most valuable contributions you can make, even without writing any code.
This is the key architectural decision. ZFS is a kernel module — the test suite needs to:
spl.ko and zfs.ko kernel modulesDocker containers share the host kernel. If you load ZFS modules inside a container, they affect your entire host system. A crashing test could take down your workstation. With a QEMU/KVM virtual machine, you get a fully isolated kernel — crashes stay inside the VM, and you can just reboot it.
┌─────────────────────────────────────────────────┐│ HOST (your workstation) ││ Arch Linux · Kernel 6.18.8 · Your ZFS pools ││ ││ ┌───────────────────────────────────────────┐ ││ │ QEMU/KVM VM │ ││ │ Arch Linux · Kernel 6.18.7 │ ││ │ │ ││ │ ┌─────────────┐ ┌───────────────────┐ │ ││ │ │ spl.ko │ │ ZFS Test Suite │ │ ││ │ │ zfs.ko │ │ (file-backed │ │ ││ │ │ (from src) │ │ loopback vdevs) │ │ ││ │ └─────────────┘ └───────────────────┘ │ ││ │ │ ││ │ If something crashes → only VM affected │ ││ └──────────────────────────────────┬────────┘ ││ SSH :2222 ←┘ │└─────────────────────────────────────────────────┘
We use the official Arch Linux cloud image — a minimal, pre-built qcow2 disk image maintained by the Arch Linux project. It’s designed for cloud/VM environments and includes:
This is NOT the “archzfs” project (archzfs.com provides prebuilt ZFS packages). We named our VM hostname “archzfs” for convenience, but we build ZFS entirely from source.
The cloud-init seed image is a tiny ISO that tells cloud-init how to configure the VM on first boot — what user to create, what password to set, what hostname to use. On a real cloud provider, this comes from the metadata service; for local QEMU, we create it manually.
# Install QEMU and toolssudo pacman -S qemu-full cdrtools# Optional: virt-manager for GUI managementsudo pacman -S virt-manager libvirt dnsmasqsudo systemctl enable --now libvirtdsudo usermod -aG libvirt $USER
mkdir ~/zfs-testvm && cd ~/zfs-testvm# Download the latest Arch Linux cloud imagewget https://geo.mirror.pkgbuild.com/images/latest/Arch-Linux-x86_64-cloudimg.qcow2# Resize to 40G (ZFS tests need space for file-backed vdevs)qemu-img resize Arch-Linux-x86_64-cloudimg.qcow2 40G
mkdir -p /tmp/seed# User configurationcat > /tmp/seed/user-data << 'EOF'#cloud-confighostname: archzfsusers: - name: arch shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: false plain_text_passwd: test123ssh_pwauth: trueEOF# Instance metadatacat > /tmp/seed/meta-data << 'EOF'instance-id: archzfs-001local-hostname: archzfsEOF# Build the seed ISOmkisofs -output seed.img -volid cidata -joliet -rock /tmp/seed/
qemu-system-x86_64 \ -enable-kvm \ -m 8G \ -smp 8 \ -drive file=Arch-Linux-x86_64-cloudimg.qcow2,if=virtio \ -drive file=seed.img,if=virtio,format=raw \ -nic user,hostfwd=tcp::2222-:22 \ -nographic
What each flag does:
| Flag | Purpose |
|---|---|
-enable-kvm | Use hardware virtualization (huge performance gain) |
-m 8G | 8GB RAM (ZFS ARC cache benefits from more) |
-smp 8 | 8 virtual CPUs (adjust to your host) |
-drive ...qcow2,if=virtio | Boot disk with virtio for best I/O |
-drive ...seed.img | Cloud-init configuration |
-nic user,hostfwd=... | User-mode networking with SSH port forward |
-nographic | Serial console (no GUI window needed) |
Login will appear on the serial console. Credentials: arch / test123.
You can also SSH from another terminal:
ssh -p 2222 arch@localhost
sudo pacman -Syu --noconfirm \ base-devel git autoconf automake libtool python \ linux-headers libelf libaio openssl zlib \ ksh bc cpio fio inetutils sysstat jq pax rsync \ nfs-utils lsscsi xfsprogs parted perf
# Clone YOUR fork (replace with your GitHub username)git clone https://github.com/YOUR_USERNAME/zfs.gitcd zfs# Build everything./autogen.sh./configure --enable-debugmake -j$(nproc)
The build compiles:
spl.ko, zfs.ko) against the running kernel headerszpool, zfs, zdb, etc.)Build time: ~5-10 minutes with 8 vCPUs.
Note: You’ll see many objtool warnings about spl_panic() and luaD_throw() missing __noreturn. These are known issues on newer kernels and don’t affect functionality.
# Load the ZFS kernel modulessudo scripts/zfs.sh# Verify modules are loadedlsmod | grep zfs# Run the FULL test suite (4-8 hours)scripts/zfs-tests.sh -v 2>&1 | tee /tmp/zts-full.txt# Or run a single test (for quick validation)scripts/zfs-tests.sh -v \ -t /home/arch/zfs/tests/zfs-tests/tests/functional/cli_root/zpool_create/zpool_create_001_pos.ksh
Important notes on zfs-tests.sh:
-t flag requires absolute paths to individual .ksh test filesnet and pamtester are okay — only NFS/PAM tests will skipFrom your host machine:
# Copy the summary logscp -P 2222 arch@localhost:/tmp/zts-full.txt ~/zts-full.txt# Copy detailed per-test logsscp -r -P 2222 arch@localhost:/var/tmp/test_results/ ~/zfs-test-results/
The test results summary looks like:
Results SummaryPASS 2847FAIL 12SKIP 43Running Time: 05:23:17
What to look for:
/var/tmp/test_results/<timestamp>/ each test has stdout/stderr outputIf you find new failures, file a GitHub issue at openzfs/zfs with:
Title: Test failure: <test_name> on Linux 6.18.7 (Arch Linux)**Environment:**- OS: Arch Linux (cloud image)- Kernel: 6.18.7-arch1-1- ZFS: built from master (commit <hash>)- VM: QEMU/KVM, 8 vCPU, 8GB RAM**Failed test:**<test name and path>**Test output:**<paste relevant log output>**Expected behavior:**Test should PASS (passes on kernel X.Y.Z / other distro)
Snapshot the VM after setup to avoid repeating the build:
# On host, after VM is set up and ZFS is builtqemu-img snapshot -c "zfs-built" Arch-Linux-x86_64-cloudimg.qcow2# Restore laterqemu-img snapshot -a "zfs-built" Arch-Linux-x86_64-cloudimg.qcow2
Run a subset of tests by test group:
# All zpool testsfor t in /home/arch/zfs/tests/zfs-tests/tests/functional/cli_root/zpool_*/*.ksh; do echo "$t"done# Run tests matching a patternfind /home/arch/zfs/tests/zfs-tests/tests/functional -name "*.ksh" | grep snapshot | head -5
Increase disk space if tests fail with ENOSPC:
# On host (VM must be stopped)qemu-img resize Arch-Linux-x86_64-cloudimg.qcow2 +20G# Inside VM after rebootsudo growpart /dev/vda 3 # or whichever partitionsudo resize2fs /dev/vda3
Suppress floppy drive errors (the harmless I/O error, dev fd0 messages):
# Add to QEMU command line:-fda none
This guide was written while setting up an OpenZFS test environment for kernel 6.18.7 on Arch Linux. The same approach works for any Linux distribution that provides cloud images — just swap the base image and package manager commands.
QEMU/KVM + Arch Linux Cloud Image + ZFS from Source
ZFS tests need to load and unload kernel modules (spl.ko, zfs.ko). Docker containers share the host kernel — loading ZFS modules in a container affects your host system and could crash it. A QEMU/KVM VM has its own isolated kernel, so module crashes stay contained. The VM also provides loopback block devices for creating test zpools, which Docker can’t safely offer.
Setup Flow
Download official Arch cloud image. Resize qcow2 to 40G with qemu-img resize.
Write user-data + meta-data YAML. Build ISO seed with mkisofs.
qemu-system-x86_64 -enable-kvm -m 8G -smp 8 with SSH forward on 2222.
pacman -S base-devel git ksh bc fio linux-headers and test dependencies.
Clone fork → autogen.sh → configure → make -j8
scripts/zfs.sh loads modules. zfs-tests.sh -v runs the suite (4-8h).
SCP results to host. Compare against known failures. Report regressions on GitHub.
Most important OpenZFS announcement: AnyRaid
This is a new vdev type based on mirror or Raid-Zn to build a vdev from disks of any size where datablocks are striped in tiles (1/64 of smallest disk or 16G). Largest disk can be 1024x of smallest with maximum of 256 disks per vdev. AnyRaid Vdevs can expand, shrink and auto rebalance on shrink or expand.
Basically the way Raid-Z should have be from the beginning and propably the most superiour flexible raid concept on the market.
Large Sector/ Labels
Large format NVMe require them
Improve S3 backed pools efficiency
Blockpointer V2
More uberblocks to improve recoverability of pools
Amazon FSx
fully managed OpenZFS storage as a service
Zettalane storage
with HA in mind, based on S3 object storage
This is nice as they use Illumos as base
Storage grow (be prepared)
no end in sight (AI needs)
cost: hd=1x, SSD=6x
Discussions:
mainly around realtime replication, cluster options with ZFS, HA and multipath and object storage integration
special_small_blocks to land ZVOL writes on special vdevs (#14876), and allow non-power of two values (#17497)zfs rewrite -P which preserves logical birth time when possible to minimize incremental stream size (#17565)-a|--all option which scrubs, trims, or initializes all imported pools (#17524)zpool scrub -S -E to scrub specific time ranges (#16853)