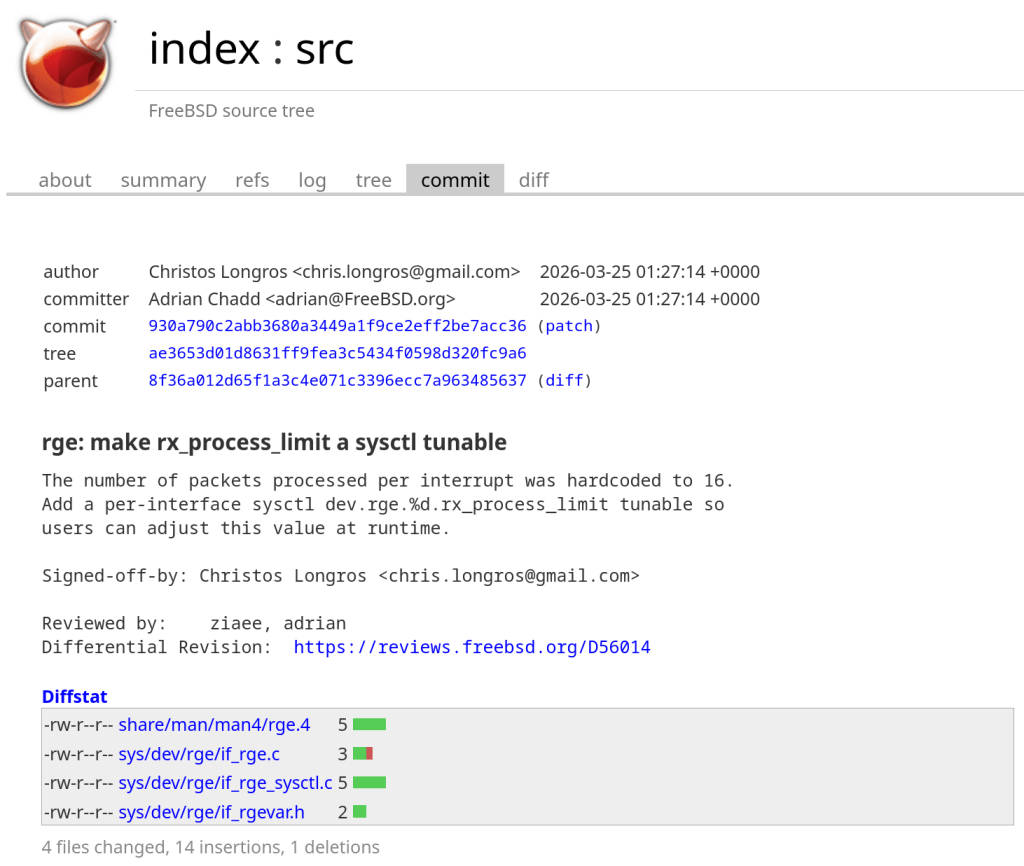
TL;DR: Many professional societies run Zoom-based webinar series where you need to attend a minimum percentage of sessions to earn a certificate. I used Claude to audit my attendance history directly from Gmail, then automated the whole process with a Google Apps Script that detects new Zoom registration emails and adds calendar events — so you never miss a session again.
The Problem: Tracking Attendance for Certificate Programmes
Many professional associations now run structured online education programmes through Zoom, where attendance is tracked and a certificate is awarded to participants who reach a certain threshold — typically 70% of live sessions. The problem is that life gets in the way: you register for a session, forget about it, and only realise you missed it when the “sorry you couldn’t make it” email arrives. Over a multi-month programme, these misses add up quietly.
The good news is that Zoom’s post-event emails are remarkably consistent and machine-readable. This makes the whole problem automatable.
Step 1: Reconstructing Your Attendance History from Gmail
Zoom always sends one of two emails after a webinar ends:
- “Thank you for attending…” — you were present
- “We’re sorry you were not able to attend…” — you registered but missed it
This means your full attendance history is sitting in your Gmail inbox, waiting to be counted. To find it, search Gmail using a query like:
from:no-reply@zoom.us ("thank you for attending" OR "sorry that you were not able") [your-series-keyword]
Replace [your-series-keyword] with something specific to your programme — the organiser’s domain, the series name, or any unique phrase that appears in your webinar emails. The results give you a complete attended/missed breakdown to calculate your current attendance rate.
Step 2: Automating Calendar Events with Google Apps Script
Google Apps Script is a free JavaScript runtime that runs inside your Google account with direct access to Gmail and Google Calendar. No server, no third-party service, no cost.
The script does the following every hour:
- Searches Gmail for new Zoom registration confirmation emails matching your programme’s keywords
- Parses the webinar title and date/time from the email body
- Maps Zoom’s city-based timezone strings to proper IANA timezones
- Checks for duplicate calendar events before creating anything
- Creates a Google Calendar event with a 1-day email reminder and a 1-hour popup reminder
- Labels the processed email so it is never processed twice
Parsing the Zoom Email Format
The trickiest part was reliably extracting the date and time. Zoom confirmation emails always contain a line like:
Date & Time Oct 23, 2025 06:00 PM Amsterdam, Berlin, Rome, Stockholm, Vienna
The key insight is to anchor the regex on Date & Time rather than trying to detect a date anywhere in the body — robust across different webinar topics and templates:
const anchored = /Date\s*&\s*Time\s+(\w{3}\.?\s+\d{1,2},?\s+\d{4})\s+(\d{1,2}:\d{2}\s*[AP]M)(.*)/i;
const m = text.match(anchored);
// m[1] = "Oct 23 2025" m[2] = "06:00 PM" m[3] = "Amsterdam, Berlin, ..."
Zoom expresses timezones as a city list rather than an IANA string. A mapping function handles the conversion:
function mapTimezone(raw) {
const s = (raw || "").toLowerCase();
if (/amsterdam|berlin|rome|vienna|stockholm/.test(s)) return "Europe/Berlin";
if (/london|dublin|bst|gmt/.test(s)) return "Europe/London";
if (/eastern|new york|toronto/.test(s)) return "America/New_York";
// ... other timezones ...
return "Europe/Berlin"; // default
}
Deduplication
The script checks the calendar for an existing event with a matching title near the same date, and applies a Gmail label (Webinar-Added) to every processed thread — excluding it from future queries. Safe to re-run as many times as needed.
Setup: 2 Minutes
- Go to script.google.com → New project
- Paste the full script, replacing all default content
- Update the
CONFIGblock — specifically thekeywordsarray - Select
createProcessedLabel→ click ▶ Run - Select
installTrigger→ click ▶ Run - Optionally run
backfillHistoricalWebinarsonce for past emails
Google will show a warning: “Google hasn’t verified this app.” This is normal for personal Apps Scripts — click Advanced → Go to [project name] (unsafe) and grant permissions. You are the developer and sole user.
Adapting for Your Own Programme
Everything lives in one CONFIG object at the top:
const CONFIG = {
processedLabel: "Webinar-Added",
calendarId: "primary",
defaultDurationMins: 90,
emailReminderMins: 24 * 60, // 1 day before
popupReminderMins: 60, // 1 hour before
// Change these to match your programme
keywords: [
"your-society-name", "your-series-name", "other-keyword",
],
};
Replace the keywords values with terms unique to your series — the rest works unchanged for any Zoom-hosted webinar programme.
What This Doesn’t Do
- It doesn’t register you. The script only acts after you register — it creates the calendar reminder from the confirmation email.
- It doesn’t track actual attendance. Events are created from registration confirmations, not post-event emails. Your official record is with the organiser.
- It requires a consistent email address. Most programmes track attendance by email. Register with the same address every time.
Full Script
The complete script is available on my GitHub. MIT licensed — adapt freely.
Tags: Google Apps Script, Zoom, Webinar, Automation, Gmail, Google Calendar, CME, Medical Education, Professional Development