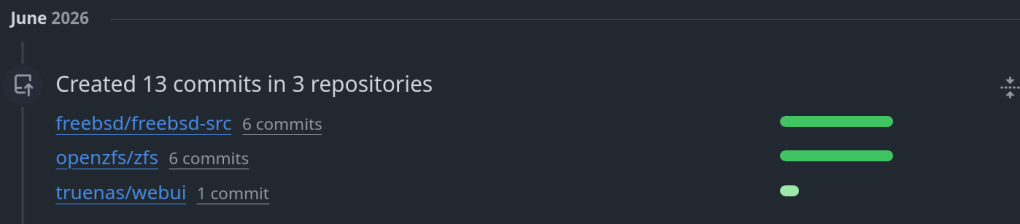
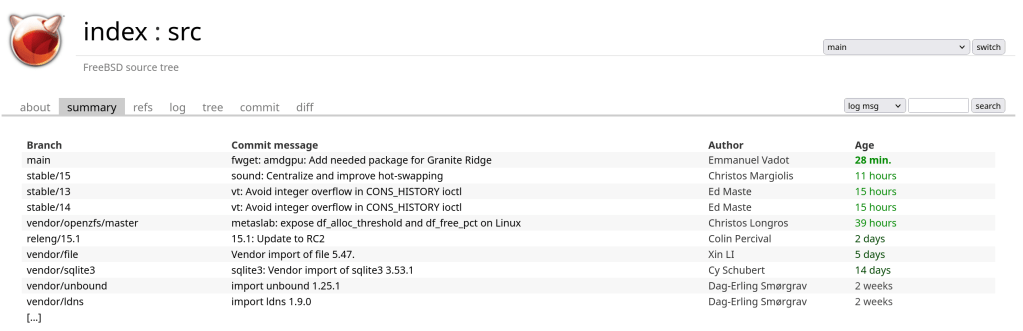
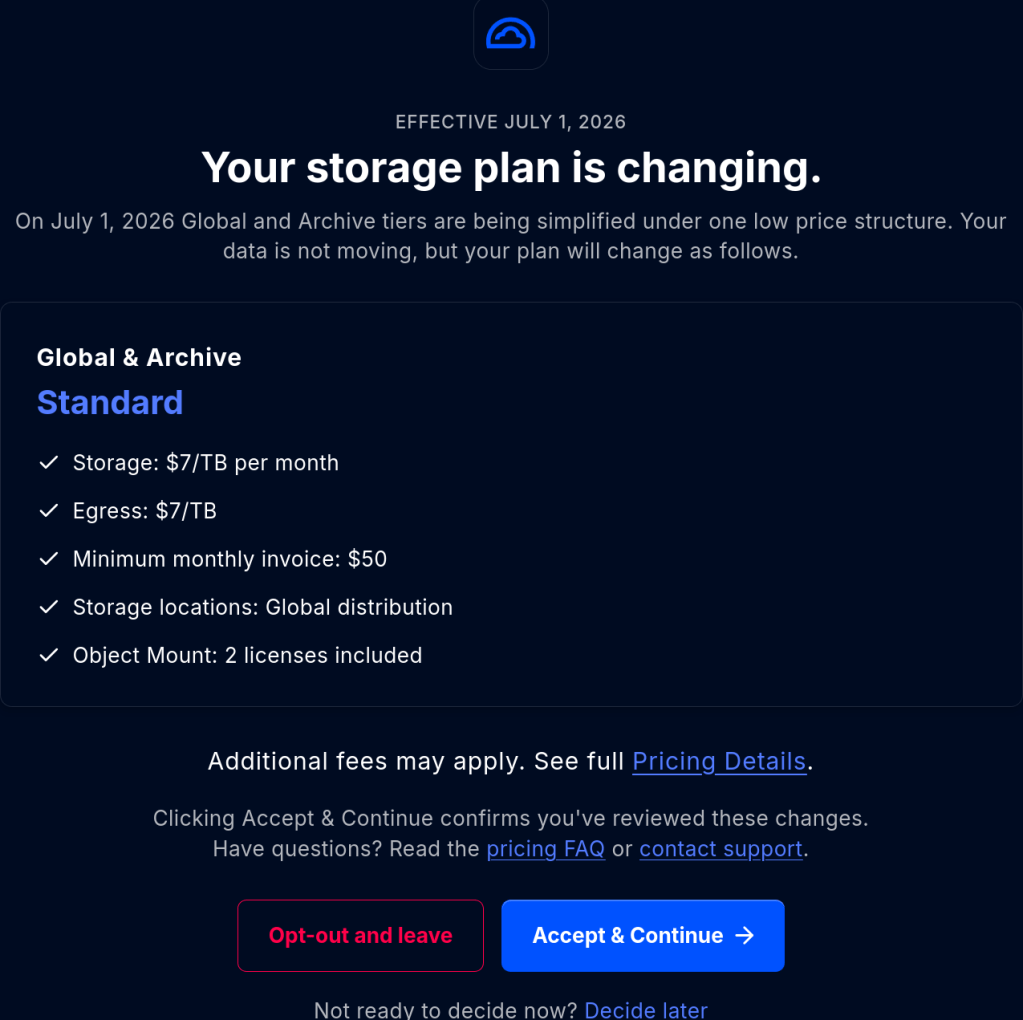
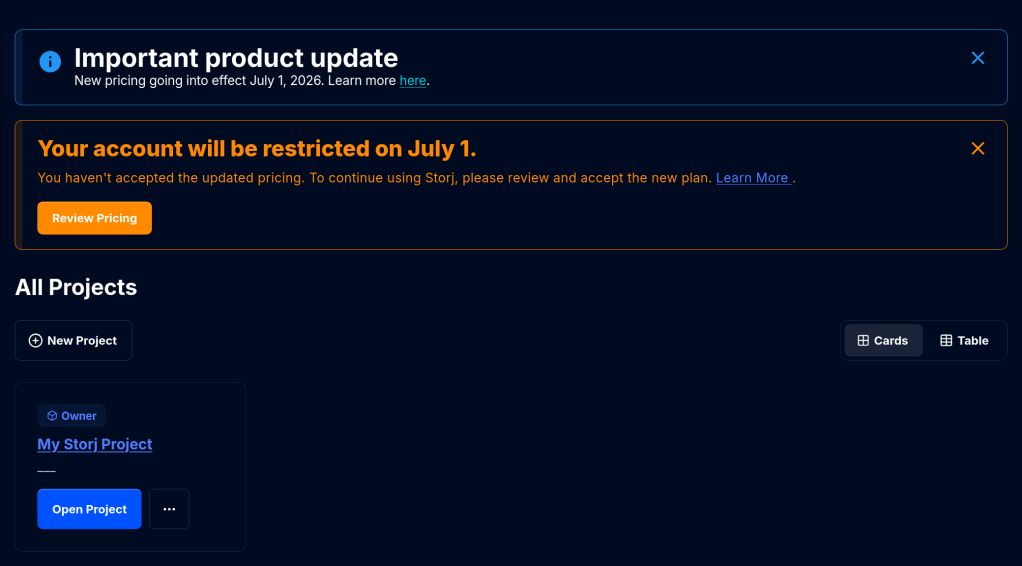
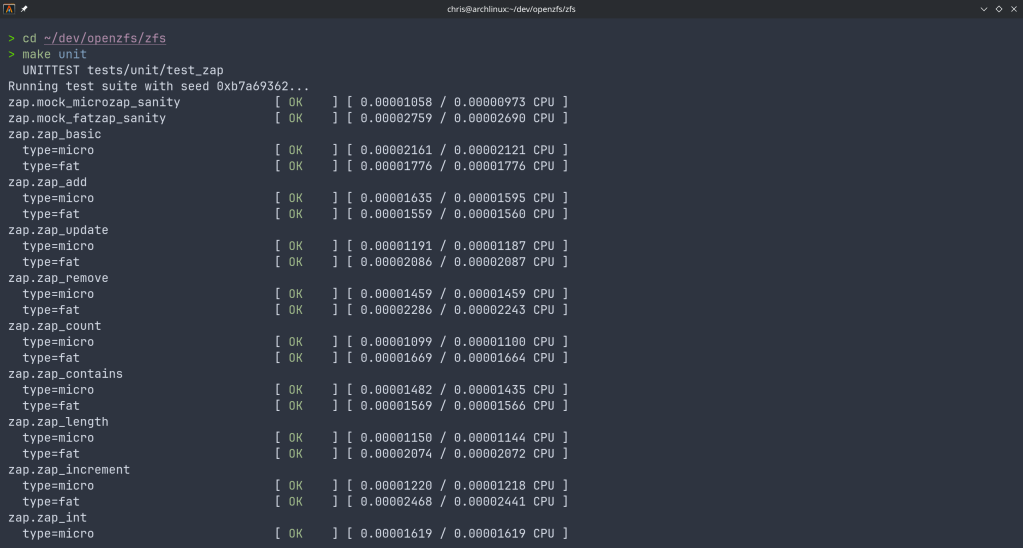
> make unit
UNITTEST tests/unit/test_zap
Running test suite with seed 0x8f27c767...
zap.mock_microzap_sanity [ OK ] [ 0.00001072 / 0.00001014 CPU ]
zap.mock_fatzap_sanity [ OK ] [ 0.00002379 / 0.00002299 CPU ]
zap.zap_basic
type=micro [ OK ] [ 0.00002169 / 0.00002172 CPU ]
type=fat [ OK ] [ 0.00002119 / 0.00002120 CPU ]
zap.zap_add
type=micro [ OK ] [ 0.00000964 / 0.00000965 CPU ]
type=fat [ OK ] [ 0.00002727 / 0.00002665 CPU ]
zap.zap_update
type=micro [ OK ] [ 0.00001184 / 0.00001185 CPU ]
type=fat [ OK ] [ 0.00001811 / 0.00001806 CPU ]
zap.zap_remove
type=micro [ OK ] [ 0.00001190 / 0.00001192 CPU ]
type=fat [ OK ] [ 0.00002998 / 0.00002978 CPU ]
zap.zap_count
type=micro [ OK ] [ 0.00001882 / 0.00001843 CPU ]
type=fat [ OK ] [ 0.00001707 / 0.00001706 CPU ]
zap.zap_contains
type=micro [ OK ] [ 0.00001400 / 0.00001359 CPU ]
type=fat [ OK ] [ 0.00001650 / 0.00001651 CPU ]
zap.zap_length
type=micro [ OK ] [ 0.00001039 / 0.00001038 CPU ]
type=fat [ OK ] [ 0.00002450 / 0.00002413 CPU ]
zap.zap_increment
type=micro [ OK ] [ 0.00001459 / 0.00001457 CPU ]
type=fat [ OK ] [ 0.00002773 / 0.00002737 CPU ]
zap.zap_int
type=micro [ OK ] [ 0.00002339 / 0.00002288 CPU ]
type=fat [ OK ] [ 0.00003203 / 0.00003164 CPU ]
zap.zap_int_keys
type=micro [ OK ] [ 0.00001585 / 0.00001579 CPU ]
type=fat [ OK ] [ 0.00004489 / 0.00004479 CPU ]
zap.microzap_stats [ OK ] [ 0.00001210 / 0.00001212 CPU ]
zap.fatzap_stats [ OK ] [ 0.00001901 / 0.00001899 CPU ]
zap.uint64_keys [ OK ] [ 0.00001770 / 0.00001764 CPU ]
zap.cursor
type=micro [ OK ] [ 0.00002167 / 0.00002166 CPU ]
type=fat [ OK ] [ 0.00003274 / 0.00003226 CPU ]
zap.cursor_serialize
type=micro [ OK ] [ 0.00002177 / 0.00002173 CPU ]
type=fat [ OK ] [ 0.00002936 / 0.00002924 CPU ]
zap.cursor_release_unused
type=micro [ OK ] [ 0.00001119 / 0.00001115 CPU ]
type=fat [ OK ] [ 0.00001867 / 0.00001856 CPU ]
zap.cursor_release_advance
type=micro [ OK ] [ 0.00001058 / 0.00001056 CPU ]
type=fat [ OK ] [ 0.00001544 / 0.00001544 CPU ]
zap.cursor_release_empty
type=micro [ OK ] [ 0.00000918 / 0.00000907 CPU ]
type=fat [ OK ] [ 0.00001564 / 0.00001563 CPU ]
zap.cursor_release_one
type=micro [ OK ] [ 0.00001696 / 0.00001662 CPU ]
type=fat [ OK ] [ 0.00001843 / 0.00001841 CPU ]
zap.zap_value_search
type=micro [ OK ] [ 0.00001555 / 0.00001551 CPU ]
type=fat [ OK ] [ 0.00002377 / 0.00002379 CPU ]
zap.zap_value_search_mask
type=micro [ OK ] [ 0.00001525 / 0.00001524 CPU ]
type=fat [ OK ] [ 0.00002293 / 0.00002288 CPU ]
41 of 41 (100%) tests successful, 0 (0%) test skipped.